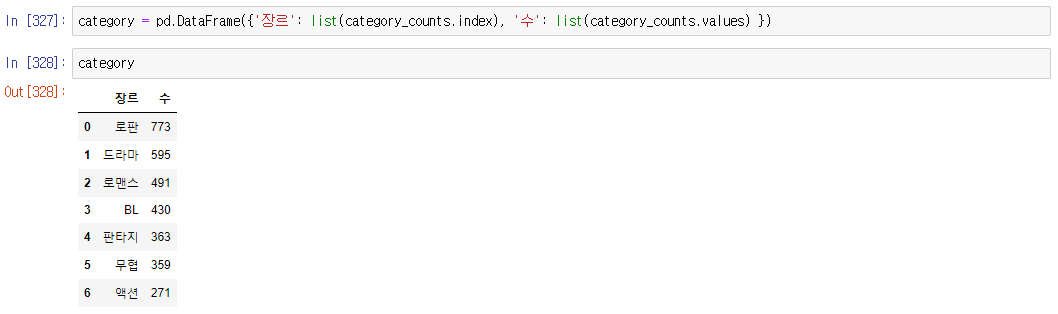
안녕하세요! 네이버 뉴스가 24년 1월 25일부터 페이지가 보여주는 방식이 변경되면서, 이전 포스팅에서 진행했던 첫 번째 코드를 사용할 수 없게 되었습니다.
그래서 변경된 페이지에서 적용되는 크롤링 코드를 새로 가지고 왔습니다!
※ 두 번째 코드는 동일하게 적용됩니다.
해당 포스팅에서는 전체 코드만 첨부합니다.
크롤링할 페이지의 설명, 크롤링 진행 방식, 이전 크롤링 코드가 궁금하신 분들은 아래 링크에서 확인하실 수 있습니다.
[Crawling] 네이버 뉴스 크롤링 - 1
안녕하세요. 크롤링에서 가장 첫 포스팅을 네이버 뉴스 크롤링으로 하게 되었어요. 아무래도 바쁜 일상 속에서 매일 뉴스 기사를 파악하는 부분이 시간적으로 힘들었는데, 크롤링하고 데이터
yhj9855.com
크롤링의 자세한 과정이 궁금하신 분들은 아래 링크를 봐주시면 됩니다!
<첫 번째 코드의 자세한 과정>
[Crawling] 네이버 뉴스 크롤링 - 2 (변경)
안녕하세요. 오늘은 기존에 작성한 네이버 뉴스 클로링 코드에서 첫 번째 코드의 자세한 크롤링 과정을 포스팅 하겠습니다.새롭게 변경된 첫 번째 코드의 자세한 크롤링 과정입니다! 네이버 뉴
yhj9855.com
<두 번째 코드의 자세한 과정>
[Crawling] 네이버 뉴스 크롤링 - 3
안녕하세요. 오늘은 기존에 작성한 네이버 뉴스 크롤링 코드에서 두 번째 코드의 자세한 크롤링 과정을 포스팅 하겠습니다. 네이버 뉴스 크롤링 전체 코드를 확인하고 싶으신 분들은 아래 링크
yhj9855.com
[첫 번째 코드]
전체 코드
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
from selenium.webdriver.common.by import By
from openpyxl import *
# 2024.01.25 부터 변경된 네이버 기사를 새로 크롤링하기 위해 만든 코드
link = 'https://news.naver.com/breakingnews/section/105/229?date='
# 스크랩 하고 싶은 날짜를 년도월일 나열해준다.
# 날짜를 쉽게 바꾸기 위해 date를 따로 선언해준다.
date = '20250107'
# 메인 링크는 링크에 날짜가 붙은 구조이기 때문에 이렇게 작성해준다.
main_link = link + date
Main_link = pd.DataFrame({'number' : [], 'title' : [], 'link' : []})
# Selenium 4 버전 이상 부터는 해당 방법으로 사용해야 driver 인식이 된다.
service = Service('chromedriver.exe')
driver = webdriver.Chrome(service=service)
driver.get(main_link)
time.sleep(3)
# 기사 더보기 버튼
more_button = driver.find_element(By.CLASS_NAME, 'section_more_inner._CONTENT_LIST_LOAD_MORE_BUTTON')
# 기사 더보기가 몇 개가 있을지 모르기 때문에 오류가 날 때까지 누르는 것으로 한다.
# 여기서 발생하는 오류란 버튼을 찾을 수 없다 즉, 버튼이 없을 때 발생하는 오류이다.
while True :
try :
more_button.click()
time.sleep(3)
except :
break
articles = driver.find_elements(By.CLASS_NAME, 'sa_text_title._NLOG_IMPRESSION')
for i in range(len(articles)) :
title = articles[i].text.strip()
link = articles[i].get_attribute('href')
li = [i+1, title, link]
Main_link.loc[i] = li
excel_name = 'news_' + date + '.xlsx'
with pd.ExcelWriter(excel_name) as writer :
Main_link.to_excel(writer, sheet_name='링크', index=False)[두 번째 코드]
전체 코드
from bs4 import BeautifulSoup
import requests
import pandas as pd
from openpyxl import *
import time
import urllib
# 첫 번째 코드에서 지정한 뉴스의 링크들이 담긴 파일
link = pd.read_excel('news_20231222.xlsx')
# 엑셀 파일이 헷갈리지 않게 최종 결과파일에도 날짜를 넣어줌
excel_name = 'news_detail_20231222.xlsx'
Main_link = list(link['link'])
# number: 기사의 수, title: 기사의 제목, information: 본문 내용, link: 기사의 링크
Information = pd.DataFrame({'number' : [], 'title' : [], 'information' : [], 'link' : []})
# 본문 내용만 추가하면 되기 때문에 데이터 프레임에 미리 나머지 내용을 담아줌
Information['number'] = link['number']
Information['title'] = link['title']
Information['link'] = link['link']
information = []
for main_link in Main_link :
# 기사가 전체적으로 2개의 구조를 가지고 있음 (게임/리뷰 카테고리에 한하여)
# 하나의 구조를 기준으로 삼고, 해당 부분에서 오류가 발생하면 다음 구조의 기사로 판단
try :
response = requests.get(main_link, headers={'User-Agent':'Moailla/5.0'})
if response.status_code == 200 :
html = response.content
soup = BeautifulSoup(html, 'html.parser')
# 기사의 본문 내용만 담고 있는 부분
info = soup.find('div', {'id' : 'newsct_article'}).text.strip()
# 기사 내용 데이터 분석을 위해서 줄바꿈을 띄어쓰기로 변경
info = info.replace('\n', '')
information.append(info)
except :
# 다른 구조의 기사 크롤링 코드
# 여기서 오류가 나는 경우는 게임/리뷰 기사가 아닌 다른 카테고리의 기사로 판단
try :
response = requests.get(main_link, headers={'User-Agent':'Moailla/5.0'})
if response.status_code == 200 :
html = response.content
soup = BeautifulSoup(html, 'html.parser')
# 기사의 본문 내용을 담고 있는 부분
info = soup.find('div', {'id' : 'newsEndContents'}).text.strip()
info = info.replace('\n', '')
# 해당 구조의 기사는 기자의 정보가 본문과 무조건 같이 존재
# 기자의 정보 부분은 필요가 없기 때문에 기자 정보의 기준점이 되는 부분을 찾음
# 기자의 정보 기준이 기사제공이라는 단어이기 때문에 그 이후는 삭제
end = info.index('기사제공')
info = info[:end]
information.append(info)
# 다른 카테고리의 기사가 들어올 경우에는 정보를 담지 않는 것으로 함
except Exception as e :
info = ''
information.append(info)
# 오류가 발생하는 이유와 발생하는 링크를 출력하여 오류를 확인하는 장치
#print(e)
#print(main_link)
Information['information'] = information
with pd.ExcelWriter(excel_name) as writer :
Information.to_excel(writer, sheet_name='결과값', index=False)
뉴스 크롤링 데이터를 이용한 워드클라우드 포스팅은 아래에서 확인해주세요!
[데이터 분석] 한글로 워드클라우드 만들기 (feat.네이버 뉴스 크롤링)
안녕하세요. 오늘은 크롤링 데이터로 워드클라우드(wordcloud)를 만드는 방법에 대해 포스팅 하겠습니다. 크롤링 데이터는 네이버 뉴스 크롤링을 사용할 예정입니다! 네이버 뉴스 크롤링 과정이
yhj9855.com
뉴스 크롤링 데이터를 이용한 토픽모델링 포스팅은 아래세어 확인해주세요!
[데이터 분석] 한글 데이터 토픽 모델링 진행하기
안녕하세요! 오늘은 한글 데이터로 토픽 모델링(topic modeling)을 하는 방법에 대해 포스팅 하겠습니다. 한글 데이터는 네이버 뉴스 크롤링 데이터를 사용할 예정입니다. 네이버 뉴스 크롤링 과정
yhj9855.com
코드에 대해 궁금한 부분이 있으신 분들은 댓글로 남겨주시면, 답변 드리도록 하겠습니다.

★읽어주셔서 감사합니다★
'Python(파이썬) > Crawling(크롤링)' 카테고리의 다른 글
| [Crawling] 네이버 뉴스 크롤링 - 2 (변경) (0) | 2025.01.08 |
|---|---|
| [Crawling] 원신 나무위키 (캐릭터, 성유물) 크롤링 - 1 (51) | 2024.03.31 |
| [Crawling] 네이버 뉴스 크롤링 - 3 (72) | 2024.01.11 |
| [Crawling] 네이버 뉴스 크롤링 - 2 (74) | 2024.01.08 |












![[한빛미디어]이것이 취업을 위한 코딩 테스트다 with 파이썬, 한빛미디어](https://img3c.coupangcdn.com/image/affiliate/banner/c951b891d66712c8be55c3636681e69c@2x.jpg)