대용량 결과물 저장 빅쿼리에서는 기본적으로 결과물을 csv 파일로 저장하거나, 스프레드 시트로 저장하는 기능을 제공하고 있습니다. 하지만 데이터 결과물의 용량이 너무 클 경우에는일부 데이터를 소실할 수 있는데, 데이터 분석의 특성 상 대용량의 데이터를 다루는 경우가 많기 때문에 생각보다 데이터가 소실되는 경우를 자주 경험할 수 있습니다. 이런 경우 빅쿼리와 파이썬을 연동하여 로컬 PC에 바로 csv 혹은 xlsx 파일로 결과물을 저장할 수 있습니다!
쿼리로 해결하기 힘든 데이터 처리 쿼리에서는 데이터의 직접적인 비교 등 진행하기 어려운 작업들이 있기 때문에 파이썬과 연동하여 데이터를 원하는 목적에 맞게 정제할 수 있습니다.
데이터 시각화 데이터 분석은 쿼리를 통해 데이터를 집계하는 것 뿐만 아니라, 보고서 등을 위해서 데이터를 시각화 하는 작업이 빈번하게 발생합니다. 요즘은 파이썬에서 데이터 시각화를 많이 진행하기 때문에 연동하여 진행하면, 시각화 작업을 수월하기 진행할 수 있습니다.
필요한 라이브러리 설치하기
빅쿼리와 파이썬을 연결하기 위해서는 먼저 pandas-gbq 라는 라이브러리를 설치해야 합니다.
일반 라이브러리 설치하시는 것처럼 설치해주시면 됩니다!
pip install pandas-gbq
코드 작성
파이썬 코드를 실행할 수 있는 실행기에서 아래 코드처럼 빅쿼리에서 실행이 가능한 쿼리와 함께 코드를 작성해주시면 손쉽게 빅쿼리 결과물을 로컬에 저장할 수 있습니다!
query="""
빅쿼리에서 실행할 쿼리
"""
purchase_log = pd.read_gbq(query=query, dialect='standard', project_id='빅쿼리 프로젝트 이름', auth_local_webserver=True)
purchase_log.to_csv(f"저장하고자 하는 파일 경로", sep=",", index=False, encoding='cp949')
※주의 ※
데어터의 양이 많을 경우 코드가 실행되는 시간이 길기 때문에 반드시 쿼리를 먼저 빅쿼리에서 확인 후에 파이썬에서 실행해주세요!
한글 데이터가 포함되는 경우 encoding='cp949'를 포함하지 않으면, 한글이 깨질 수 있습니다.
데이터의 양이 많다면 파일의 경로는 D드라이브로 하는 것을 추천합니다!
계정 선택
해당 코드를 처음 실행을 할 경우에는 크롬이 자동으로 뜨면서, 빅쿼리와 연결된 계정 선택 및 엑세스 요청 허가를 확인합니다.
알맞은 계정과 엑세스 허용을 하시면, 정상적으로 코드가 실행됩니다!
계정 선택의 과정은 컴퓨터마다 한 번만 진행이 됩니다.
실행이 완료되면, pandas를 이용해서 데이터를 정상적으로 로드할 수 있습니다.
1500만 정도 되는 데이터도 아주 잘 로드가 되는 것을 볼 수 있습니다!
빅쿼리는 파이썬과 연동하지 않으면 대용량 데이터를 저장하는 방법이 빅쿼리 자체에 테이블로 저장하는 방법 밖에 없기 때문에 파이썬에서 실행하는 방법을 익혀두시는 걸 추천드립니다!
이름: A.NAME → A는 ANIMAL_INS 테이블, B는 ANIMAL_OUTS 테이블을 의미합니다. → ID와 이름은 각 테이블에서 같이 포함되어 있기 때문에 어느 테이블에 존재하는지 꼭 명시를 해야합니다. → 여기서는 A, B 어느 테이블에 있는 값을 가지고 와도 동일한 값을 SELECT 합니다.
총 2개인 것을 확인할 수 있습니다.
다음으로 두 개의 테이블을 JOIN 해야하는 부분은
ANIMAL_INS 테이블과 ANIMAL_OUTS 테이블을 동시에 만족: JOIN ANIMAL_OUTS B → 두 테이블을 동시에 만족해야 하기 때문에 내부 조인을 사용하는데, JOIN 혹은 INNER JOIN 으로 표기하시면 됩니다. → ANIMAL_OUTS을 FROM에 두고, ANIMAL_INS 테이블로 JOIN을 해도 상관 없습니다.
두 테이블에서 값이 동일한 컬럼이 기준: ON A.ANIMAL_ID=B.ANIMAL_ID → 두 테이블에서 동일한 값이 여러 개 있으나, 문제에서 ANIMAL_OUTS의 ANIMAL_ID는 ANIMAL_INS의 ANIMAL_ID의 외래 키라고 하였기 때문에 ANIMAL_ID로 JOIN하는 것이 좋습니다. → NAME, ANIMAL_TYPE 과 같은 값으로 JOIN을 할 경우, 테이블 내에 중복 값으로 인해 원하는 대로 JOIN이 되지 않을 가능성이 높습니다.
위와 같은 것을 확인할 수 있습니다.
다음으로 저희가 WHERE 조건으로 확인해야 하는 부분은
보호 시작일보다 입양일이 더 빠른 동물: A.DATETIME > B.DATETIME
총 1개인 것을 확인할 수 있습니다.
마지막으로 저희가 문제에서 확인해야 하는 부분은
결과는 보호 시작일이 빠른 순으로 조회: ORDER BY A.DATETIME
총 1개인 것을 확인할 수 있습니다.
쿼리 완성하기
이제 위에서 생각한 쿼리를 SQL 실행순서에 맞게 배치해주시면 됩니다.
그렇게 완성된 쿼리는 아래와 같습니다.
SELECT
A.ANIMAL_ID, A.NAME
FROM
ANIMAL_INS A
JOIN
ANIMAL_OUTS B ON A.ANIMAL_ID = B.ANIMAL_ID
WHERE
A.DATETIME > B.DATETIME
ORDER BY
A.DATETIME
안녕하세요! 오늘은 원신 나무위키에 플레이어블 캐릭터와 성유물 카테고리의 글을 크롤링하는 코드에 대해 포스팅 진행하겠습니다.
해당 포스팅에서는 전체 코드와 결과물 이미지만 첨부합니다.
크롤링의 자세한 과정은 추후에 포스팅 진행하도록 하겠습니다.
해당 크롤링은 원신 각 캐릭터의 성유물 추천 옵션과 세트를 빠르게 파악하기 위한 데이터 수집을 목적으로 하고 있습니다!
나무위키에서 수집할 정보는 아래와 같습니다.
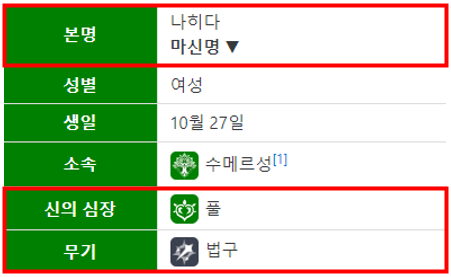
※ 사진 속 정보는 나히다를 예시로 한 것입니다.
1. 캐릭터의 이름, 속성, 무기
2. 권장 성유물 옵션
3. 추천 성유물 세트 및 설명
4. 성유물 이름, 세트 효과, 획득처
크롤링 진행 방식
크롤링은 총 3개의 코드로 진행을 합니다.
첫 번째 코드
원신 캐릭터의 상세 정보가 담긴 링크를 전부 긁어옵니다.
캐릭터의 이름과 링크만 저장하여 하나의 엑셀 파일로 저장합니다.
두 번째 코드
첫 번째 코드에서 저장한 엑셀 파일에서 각 캐릭터의 상세 정보 링크를 가져옵니다.
캐릭터의 속성, 무기, 권장 성유물 옵션, 추천 성유물 세트 및 상세 설명의 내용을 가지고 옵니다.
캐릭터의 이름, 속성, 무기 권장 성유물 옵션을 저장하여 하나의 엑셀 파일로 저장합니다.
캐릭터의 이름, 추천 성유물 세트, 상세 설명을 저장하여 하나의 엑셀 파일로 저장합니다.
엑셀 파일을 두 개로 나눈 이유는 이후에 원신 캐릭터 성유물을 조회하는 엑셀 파일을 쉽게 만들기 위해서 입니다!
세번째 코드
성유물 세트 이름, 2세트, 4세트, 획득처의 내용을 가지고 옵니다.
획득처에서 비경의 이름을 분리합니다.
성유물 세트 이름, 2세트, 4세트, 획득처, 비경의 이름을 저장하여 하나의 엑셀 파일로 저장합니다.
비경 이름을 분리한 이유는 이후 원신 캐릭터 성유물을 조회하는 엑셀 파일을 쉽게 만들기 위해서 입니다!
[실제 코드 및 결과물]
첫 번째 코드
import pandas as pd
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as E
from openpyxl import *
# 원신/캐릭터 나무위키 링크
link = 'https://namu.wiki/w/%EC%9B%90%EC%8B%A0/%EC%BA%90%EB%A6%AD%ED%84%B0'
# 나무위키는 BeautifulSoup이 먹히지 않기 때문에 동적 크롤링으로 진행
driver = webdriver.Chrome('chromedriver.exe')
driver.get(link)
time.sleep(3)
# '원소별' 버튼 클릭
button = list(driver.find_elements(By.CLASS_NAME, "_3xTXXXtF"))
button[1].click()
time.sleep(3)
Character = pd.DataFrame({'캐릭터 이름' : [], '링크' : []})
character_info = driver.find_elements(By.CLASS_NAME, "s3zppxXT")
for i in range(len(character_info)) :
character = character_info[i]
# 캐릭터 이름만 담기 위해서 데이터를 정제하는 부분
# 캐릭터의 소개가 끝나는 부분
if character.text == '취소선' :
break
# 주인공 캐릭터인 아이테르와 루미네는 데이터 수집에서 제외
# 캐릭터 이름이 아닌데, 들어온 정보는 모두 제외
if character.text == '' or '원신' in character.text or '아이테르' in character.text or character.text in ['불', '물', '바람', '번개', '풀', '얼음', '바위'] :
pass
else :
# 캐릭터의 이름
name = character.text
# 캐릭터의 이름이 길 경우, 엔터로 구분이 되어있기 때문에 이를 띄어쓰기로 변경
if '\n' in name :
name = name.replace('\n', ' ')
Char = [name, str(character.get_attribute('href'))]
Character.loc[i] = Char
with pd.ExcelWriter('genshin_link.xlsx') as writer :
Character.to_excel(writer, sheet_name='링크', index=False)
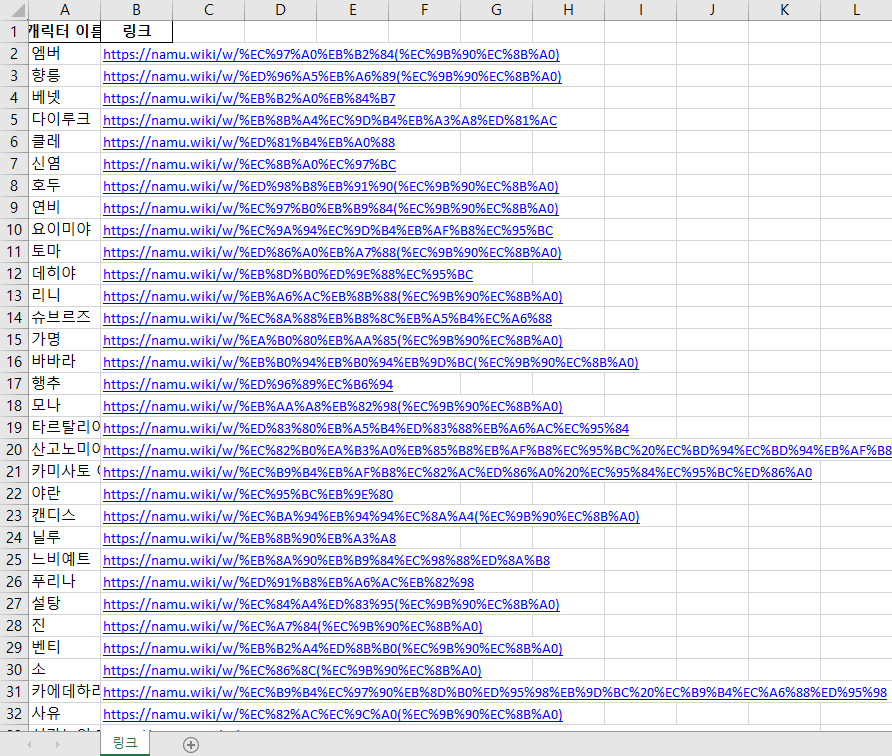
첫 번째 코드 결과물
두 번째 코드
import pandas as pd
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as E
from openpyxl import *
# 캐릭터의 이름과 상세정보 링크가 담긴 엑셀 파일
link = pd.read_excel('genshin_link.xlsx')
Main_link = list(link['링크'])
Character = list(link['캐릭터 이름'])
Information = pd.DataFrame({'캐릭터 이름' : [], '무기' : [], '시간의 모래' : [], '공간의 성배' : [], '이성의 왕관' : [], '부옵션' : []})
Relic_Information = pd.DataFrame({'캐릭터 이름' : [], '성유물' : [], '평가': []})
driver = webdriver.Chrome('chromedriver.exe')
# 엑셀 전체 인덱스를 의미
# 저장할 엑셀이 두 개이기 때문에 인덱스도 두 개가 필요
total_index = 0
relic_index = 0
# 특정 캐릭터의 상세정보에서 오류가 발생할 경우을 대비
try :
for k in range(len(Main_link)) :
driver.get(Main_link[k])
time.sleep(3)
# 캐릭터의 무기 수집 과정
attack = driver.find_elements(By.CLASS_NAME, 'cIflhYhI')
for i in range(len(attack)) :
if '무기' == attack[i].text :
attack_index = i+1
break
weapon = attack[attack_index].text
# 캐릭터의 성유물 수집 과정
info = driver.find_elements(By.CLASS_NAME, 'D7SMSdcV')
for i in range(len(info)) :
# 권장 성유물 옵션을 파악하기 위해 위치를 저장
if '권장 성유물' in info[i].text :
index = i
break
# 권성유물의 정보가 담긴 공간
sung = info[index]
# 권장 성유물 옵션 수집 과정
options = sung.find_elements(By.CLASS_NAME, 'cIflhYhI')
Option = [Character[k], weapon]
for j in range(len(options)) :
# 권장 성유물 옵션에서 필요한 정보가 들어있는 부분
if j in [4, 5, 6, 8] :
option = options[j].text
# 옵션이 여러 개일 경우, 줄바꿈으로 구분하기 때문에 이를 / 구분으로 변경
if '\n' in option :
option = option.replace('\n', ' / ')
Option.append(option)
# 권장 성유물의 옵션만 담는 부분
Information.loc[total_index] = Option
total_index = total_index+1
# 추천 성유물 세트 및 상세 설명 수집 과정
sets = sung.find_elements(By.CLASS_NAME, 'W078FM6Z')
# 성유물 세트는 캐릭터마다 여러 개 존재하기 때문에 이를 구분하기 위한 부분
character_number = 1
for j in range(len(sets)) :
# li로 구분되어 있는데, 그 안에 div가 같이 들어가 있기 때문에 문제가 발생한다.
relic_info = list(sets[j].text.split('\n'))
for m in range(len(relic_info)) :
# 실제 정보가 들어가 있는 부분
if m%2 == 1:
one_set = relic_info[m-1]
set_info =relic_info[m]
character_name = Character[k]+'%d' %(character_number)
Option = [character_name, one_set, set_info]
Relic_Information.loc[relic_index] = Option
character_number = character_number+1
relic_index = relic_index+1
except Exception as e :
print(e)
print(Main_link[k])
with pd.ExcelWriter('genshin.xlsx') as writer :
Information.to_excel(writer, sheet_name='성유물 옵션', index=False)
with pd.ExcelWriter('genshin_set_relic.xlsx') as writer :
Relic_Information.to_excel(writer, sheet_name='성유물', index=False)
두 번째 코드 결과물
세 번째 코드
import pandas as pd
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as E
from openpyxl import *
# 원신/성유물 나무위키 링크
link = 'https://namu.wiki/w/%EC%9B%90%EC%8B%A0/%EC%84%B1%EC%9C%A0%EB%AC%BC'
driver = webdriver.Chrome('chromedriver.exe')
driver.get(link)
time.sleep(3)
Relic = pd.DataFrame({'성유물 세트' : [], '2세트' : [], '4세트' : [], '획득처' : [], '비경' : []})
total_index = 0
# 성유물 세트 효과 수집 과정
info = driver.find_elements(By.CLASS_NAME, 'TiHaw-AK._6803dcde6a09ae387f9994555e73dfd7')
for i in range(len(info)) :
# 첫 번째 성유물이 검투사의 피날레이기 때문에 해당 부분이 기준
# 여기서부터 끝까지가 성유물에 대한 정보가 존재
if '검투사' in info[i].text :
index_start = i
break
# 전체적으로 3단위로 원하는 정보가 있음
for i in range(index_start, len(info), 3) :
relic_info = info[i].text.split('\n')
# 1세트 효과가 있는 4성 성유물은 생략한다.
if '모시는 자' in relic_info[0] :
continue
# 획득처에서 비경을 구분하는 과정
if '비경' in relic_info[7] :
place_index_start = relic_info[7].index(':')
place = relic_info[7][place_index_start+2:]
if ',' in place :
place_end_index = place.index(',')
place = place[:place_end_index]
else :
place = ''
relic = [relic_info[0], relic_info[3], relic_info[5], relic_info[7], place]
Relic.loc[total_index] = relic
total_index = total_index+1
with pd.ExcelWriter('genshin_relic.xlsx') as writer :
Relic.to_excel(writer, sheet_name='성유물', index=False)
세 번째 코드 결과물
해당 데이터를 활용하여 원신 캐릭터의 성유물을 엑셀에서 쉽게 조회하는 포스팅은 아래에서 확인해주세요!
닉네임: B.NICKNAME → A는 USES_GOODS_BOARD 테이블, B는 USED_GOODS_USER 테이블을 뜻하는데, 컬럼 이름이 고유할 경우 소속 테이블을 명시해주지 않아도 SQL에서 구분이 가능합니다.
총 거래금액: SUM(A.PRICE) TOTAL_SALES → 거래금액만 존재하고, 총 거래금액은 존재하지 않기 때문에 총 거래금액은 거래금액을 합친 거라고 생각할 수 있습니다. → TOTAL_SALES는 총 거래금액의 컬럼을 별칭으로 지정한 것 입니다.
총 3개인 것을 확인할 수 있습니다.
다음으로 두 개의 테이블을 JOIN 해야하는 부분은
USES_GOODS_BOARD 테이블과 USED_GOODS_USER 테이블을 동시에 만족: JOIN USED_GOODS_USER B → 두 테이블을 동시에 만족해야 하기 때문에 내부 조인을 사용하는데, JOIN 혹은 INNER JOIN 어떤 걸 사용하셔도 상관없습니다.
두 테이블에서 값이 동일한 컬럼이 기준: ON A.WRITER_ID = B.USER_ID → ON은 조인의 조건으로 두 테이블에서 값이 동일한 것은 회원 ID 밖에 없기 때문에 해당 부분으로 조인을 진행합니다.
위와 같은 것을 확인할 수 있습니다.
다음으로 저희가 WHERE 조건으로 확인해야 하는 부분은
완료된 중고 거래: A.STATUS = 'DONE' → 여기서 주의해야할 점은 총 금액이 70만원 이상인 조건은 총 금액의 조건이고, 테이블 자체에서는 총 금액이라는 컬럼이 없기 때문에 WHERE 조건에서는 사용할 수 없습니다.
총 1개인 것을 확인할 수 있습니다.
다음으로 저희가 GROUP BY 해야하는 부분은
총 거래금액을 제외한 나머지 부분: B.USER_ID, B.NICKNAME → USER_ID 혹은 NICKNAME 각각으로 GROUP BY를 해도 두 개의 값이 모두 중복 값이 없기 때문에 동일한 결과물을 가지지만, 항상 그룹화하고 싶은 컬럼을 제외한 모든 컬럼으로 그룹화하는 것이 좋습니다.
총 금액이 70만원 이상: HAVING TOTAL_SALES >= 700000 → HAVING은 GROUP BY의 조건으로 그룹화를 통해 생성된 컬럼에 조건을 걸 수 있습니다.
위와 같은 것을 확인할 수 있습니다.
마지막으로 저희가 문제에서 확인해야 하는 부분은
결과는 총 거래금액을 기준으로 오름차순 정렬: ORDER BY TOTAL_SALES
총 1개인 것을 확인할 수 있습니다.
쿼리 완성하기
이제 위에서 생각한 쿼리를 SQL 실행순서에 맞게 배치해주시면 됩니다.
그렇게 완성된 쿼리는 아래와 같습니다.
SELECT
B.USER_ID,
B.NICKNAME,
SUM(A.PRICE) TOTAL_SALES
FROM
USED_GOODS_BOARD A
JOIN
USED_GOODS_USER B ON A.WRITER_ID = B.USER_ID
WHERE
A.STATUS = 'DONE'
GROUP BY
B.USER_ID, B.NICKNAME HAVING TOTAL_SALES >= 700000
ORDER BY
TOTAL_SALES
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
from selenium.webdriver.common.by import By
from openpyxl import *
# 2024.01.25 부터 변경된 네이버 기사를 새로 크롤링하기 위해 만든 코드
link = 'https://news.naver.com/breakingnews/section/105/229?date='
# 스크랩 하고 싶은 날짜를 년도월일 나열해준다.
# 날짜를 쉽게 바꾸기 위해 date를 따로 선언해준다.
date = '20250107'
# 메인 링크는 링크에 날짜가 붙은 구조이기 때문에 이렇게 작성해준다.
main_link = link + date
Main_link = pd.DataFrame({'number' : [], 'title' : [], 'link' : []})
# Selenium 4 버전 이상 부터는 해당 방법으로 사용해야 driver 인식이 된다.
service = Service('chromedriver.exe')
driver = webdriver.Chrome(service=service)
driver.get(main_link)
time.sleep(3)
# 기사 더보기 버튼
more_button = driver.find_element(By.CLASS_NAME, 'section_more_inner._CONTENT_LIST_LOAD_MORE_BUTTON')
# 기사 더보기가 몇 개가 있을지 모르기 때문에 오류가 날 때까지 누르는 것으로 한다.
# 여기서 발생하는 오류란 버튼을 찾을 수 없다 즉, 버튼이 없을 때 발생하는 오류이다.
while True :
try :
more_button.click()
time.sleep(3)
except :
break
articles = driver.find_elements(By.CLASS_NAME, 'sa_text_title._NLOG_IMPRESSION')
for i in range(len(articles)) :
title = articles[i].text.strip()
link = articles[i].get_attribute('href')
li = [i+1, title, link]
Main_link.loc[i] = li
excel_name = 'news_' + date + '.xlsx'
with pd.ExcelWriter(excel_name) as writer :
Main_link.to_excel(writer, sheet_name='링크', index=False)
[두 번째 코드]
전체 코드
from bs4 import BeautifulSoup
import requests
import pandas as pd
from openpyxl import *
import time
import urllib
# 첫 번째 코드에서 지정한 뉴스의 링크들이 담긴 파일
link = pd.read_excel('news_20231222.xlsx')
# 엑셀 파일이 헷갈리지 않게 최종 결과파일에도 날짜를 넣어줌
excel_name = 'news_detail_20231222.xlsx'
Main_link = list(link['link'])
# number: 기사의 수, title: 기사의 제목, information: 본문 내용, link: 기사의 링크
Information = pd.DataFrame({'number' : [], 'title' : [], 'information' : [], 'link' : []})
# 본문 내용만 추가하면 되기 때문에 데이터 프레임에 미리 나머지 내용을 담아줌
Information['number'] = link['number']
Information['title'] = link['title']
Information['link'] = link['link']
information = []
for main_link in Main_link :
# 기사가 전체적으로 2개의 구조를 가지고 있음 (게임/리뷰 카테고리에 한하여)
# 하나의 구조를 기준으로 삼고, 해당 부분에서 오류가 발생하면 다음 구조의 기사로 판단
try :
response = requests.get(main_link, headers={'User-Agent':'Moailla/5.0'})
if response.status_code == 200 :
html = response.content
soup = BeautifulSoup(html, 'html.parser')
# 기사의 본문 내용만 담고 있는 부분
info = soup.find('div', {'id' : 'newsct_article'}).text.strip()
# 기사 내용 데이터 분석을 위해서 줄바꿈을 띄어쓰기로 변경
info = info.replace('\n', '')
information.append(info)
except :
# 다른 구조의 기사 크롤링 코드
# 여기서 오류가 나는 경우는 게임/리뷰 기사가 아닌 다른 카테고리의 기사로 판단
try :
response = requests.get(main_link, headers={'User-Agent':'Moailla/5.0'})
if response.status_code == 200 :
html = response.content
soup = BeautifulSoup(html, 'html.parser')
# 기사의 본문 내용을 담고 있는 부분
info = soup.find('div', {'id' : 'newsEndContents'}).text.strip()
info = info.replace('\n', '')
# 해당 구조의 기사는 기자의 정보가 본문과 무조건 같이 존재
# 기자의 정보 부분은 필요가 없기 때문에 기자 정보의 기준점이 되는 부분을 찾음
# 기자의 정보 기준이 기사제공이라는 단어이기 때문에 그 이후는 삭제
end = info.index('기사제공')
info = info[:end]
information.append(info)
# 다른 카테고리의 기사가 들어올 경우에는 정보를 담지 않는 것으로 함
except Exception as e :
info = ''
information.append(info)
# 오류가 발생하는 이유와 발생하는 링크를 출력하여 오류를 확인하는 장치
#print(e)
#print(main_link)
Information['information'] = information
with pd.ExcelWriter(excel_name) as writer :
Information.to_excel(writer, sheet_name='결과값', index=False)
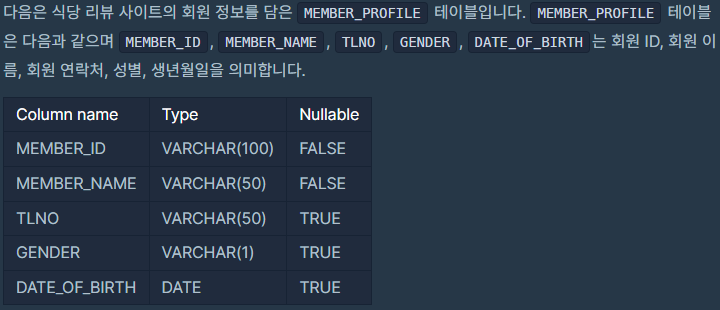
회원의 생일은 3월 : DATE_OF_BIRTH LIKE '%-03-%' → 생년월일이 '연도-월-일' 의 형태로 되어있기 때문에 월만 3월이면 되기 때문에 위와 같은 쿼리가 완성됩니다.
회원의 성별은 여성 : GENDER = 'W'
회원의 전화번호는 NULL이 아니여야 함 : TLNO IS NOT NULL
총 3개인 것을 확인할 수 있습니다.
마지막으로 저희가 문제에서 확인해야 하는 부분은
결과는 회원 ID를 기준으로 오름차순 : ORDER BY MEMBER_ID ASC
DATE_OF_BIRTH는 예시와 동일한 데이터 포맷 : DATE_FORMAT(DATE_OF_BIRTH, '%Y-%m-%d) → DATE_FORMAT 함수는 SQL에서 날짜 및 시간 값을 특정 형식의 문자열로 변환하는데 사용합니다. → 형식이 %Y-%m-%d인 이유는 M은 월의 영어 단어를 의미하고, D는 일 뒤에 영어 접미사(EX :1st, 2nd)가 붙기 때문에 숫자만 가져오고 싶을 경우, 소문자를 써야합니다.
총 2개인 것을 확인할 수 있습니다.
쿼리 완성하기
이제 위에서 생각한 쿼리를 SQL의 실행순서에 맞게 배치해주면 됩니다.
그렇게 완성된 쿼리는 아래와 같습니다.
SELECT
MEMBER_ID, MEMBER_NAME, GENDER, DATE_FORMAT(DATE_OF_BIRTH, '%Y-%m-%d')
FROM
MEMBER_PROFILE
WHERE
DATE_OF_BIRTH LIKE '%-03-%'
AND TLNO IS NOT NULL
AND GENDER = 'W'
ORDER BY
MEMBER_ID ASC