안녕하세요! 오늘은 한글 데이터로 토픽 모델링(topic modeling)을 하는 방법에 대해 포스팅 하겠습니다.
한글 데이터는 네이버 뉴스 크롤링 데이터를 사용할 예정입니다.
네이버 뉴스 크롤링 과정이 궁금하신 분은 아래 링크를 확인해주세요:)
[Crawling] 네이버 뉴스 크롤링 - 1
안녕하세요. 크롤링에서 가장 첫 포스팅을 네이버 뉴스 크롤링으로 하게 되었어요. 아무래도 바쁜 일상 속에서 매일 뉴스 기사를 파악하는 부분이 시간적으로 힘들었는데, 크롤링하고 데이터
yhj9855.com
- 토픽 모델링이란?
비지도 학습으로, 텍스트 문서 집합을 하나 이상의 추상적인 주제(=토픽)로 분류하는 작업을 말합니다.
텍스트의 구조를 파악하거나, 다량의 텍스트를 분석할 때 자주 사용되는 데이터 분석 방법입니다!
토픽 모델링을 진행하는 건 Jupyter Notebook에서 하시는 걸 추천드립니다.
Jupyter Notebook를 설치하고 사용하는 방법은 아래 링크에서 확인해주세요!
주피터 노트북(Jupyter Notebook) 사용하기
안녕하세요! 오늘은 데이터 분석에서 자주 활용하는 주피터 노트북(Jupyter Notebook) 을 사용하는 방법에 대해서 포스팅 하겠습니다. 주피터 노트북이란? 대화형 컴퓨팅 환경을 제공하는 오픈 소스
yhj9855.com
- 필요한 라이브러리 설치
토픽 모델링은 머신러닝 모델 중 LDA 모델을 사용합니다.
LDA 모델에 대한 자세한 설명은 아래 링크에서 확인해주세요!
잠재 디리클레 할당 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 자연어 처리에서 잠재 디리클레 할당(Latent Dirichlet allocation, LDA)은 주어진 문서에 대하여 각 문서에 어떤 주제들이 존재하는지를 서술하는 대한 확률적 토픽 모
ko.wikipedia.org
저는 머신러닝을 sklearn 라이브러리를 사용했기 때문에 sklearn 라이브러리를 설치해주시면 됩니다!
sklearn 라이브러리 설치가 어려우신 분들은 colab에서 진행해주셔도 됩니다.
colab의 자세한 사용법은 추후 따로 포스팅을 진행하도록 하겠습니다!
또한, 한글 텍스트 데이터를 다루고 있기 때문에 이를 다루는 라이브러리가 필요합니다.
저는 한글 텍스트를 다루는 라이브러리 중 Konply 라이브러리를 사용했습니다.
Konply 라이브러리와 관련된 자세한 설명은 아래 포스팅을 확인해주세요!
한국어 데이터 분석 필수 라이브러리 Konlpy(코엔엘파이)
안녕하세요! 오늘은 한국어 데이터 분석을 위해 꼭 필요한 Konlpy(코엔엘파이) 라이브러리에 대해서 포스팅 하겠습니다. Konlpy 란? 한국어 자연어 처리를 위한 파이썬 라이브러리 입니다. Konlpy의
yhj9855.com
- 데이터 로드 후 정제하기
필요한 라이브러리를 설치한 후에는 pandas를 사용하여 데이터를 불러옵니다.
저는 2024년 01월 17일 네이버 게임/리뷰 카테고리의 기사 크롤링 데이터를 불러와 정제를 진행하도록 하겠습니다.
# 파일 이름만 적을 때는 파일이 실행 파일과 같은 곳에 저장되어 있어야 한다.
result = pd.read_excel('파일 이름')
# 기사의 제목 데이터
Title = list(result['title'])
# 기사의 내용 데이터
Information = list(result['information'])
# 기사의 제목과 내용을 하나의 리스트에 담았다.
Total = []
for i in range(len(result)) :
Total.append(Title[i]+' '+Information[i])※ Total 데이터의 양이 너무 많아서 데이터 확인은 진행하지 않겠습니다.
- 명사로 데이터 분류하기
토픽을 제대로 분류하기 위해서는 데이터를 의미 있는 데이터만 남기는 것이 중요합니다.
그 중 가장 빠른 방법이 명사인 데이터만 남기는 것인데요.
명사로 분류를 하지 않을 경우, '있다', '있는' 과 같이 보기만 하면 이해하지 못하는 단어들이 높은 비중을 차지하는 경우가 많기 때문에 제대로 데이터 분석이 되지 않는 경우가 많이 발생합니다.
명사로 분류하기 위해 Konpy 라이브러리를 사용하려고 하는데요.
Konply가 지원하는 형태소 분석 중 저는 Komoran을 사용하였습니다.
Konply이 지원하는 다른 형태소 분석은 아래 포스팅에서 확인해주세요!
한국어 데이터 분석 필수 라이브러리 Konlpy(코엔엘파이)
안녕하세요!오늘은 한국어 데이터 분석을 위해 꼭 필요한 Konlpy(코엔엘파이) 라이브러리에 대해서 포스팅 하겠습니다. Konlpy 란?한국어 자연어 처리를 위한 파이썬 라이브러리 입니다. Konlpy의
yhj9855.com
명사로 형태소 분석을 하는 코드는 아래와 같습니다.
# 형태소 분석기로 Komoran을 사용
komoran = Komoran()
# Total 데이터를 명사로 분류한 후에 띄어쓰기로 붙여넣기 진행
# 줄바꿈으로 진행하도 상관없으나, 줄바꿈으로 진행 시, 이후 띄어쓰기 대신 모두 줄바꿈으로 변경해야한다.
total_nouns = [' '.join(komoran.nouns(doc)) for doc in Total]- 추가 전처리 진행하기
total_nouns 데이터는 이제 명사로만 이루어진 데이터입니다.
그대로 토픽 모델링을 진행해도 되지만, 생각보다 의미 없는 데이터가 많이 존재하기 때문에 추가적으로 데이터 전처리를 진행해주는 것이 좋습니다.
예를 들면 '것', '이', '등' 과 같은 단어를 삭제하기 위해서 두 글자 명사만 넣어준다거나, 특정 카테고리의 뉴스이기 때문에 자주 등장하는 명사는 제거한다거나, 기업의 이름들이 명사로 이상하게 분류되어 있는 부분을 원래 기업 이름으로 변경을 해준다거나 하는 방법으로 데이터 전처리를 진행해주시면 됩니다.
제가 진행한 전처리 코드는 아래와 같습니다.
# 추가 데이터 전처리 과정
for i in range(len(total_nouns)) :
# 자주 등장하는 단어들을 꾸준히 붙여준다. (기업 이름 등)
# total_nouns[i]]가 하나의 문자열이기 때문에 reaplace를 통해 변경한다.
total_nouns[i] = total_nouns[i].replace('위 메이드', '위메이드')
total_nouns[i] = total_nouns[i].replace('위 믹스', '위믹스')
total_nouns[i] = total_nouns[i].replace('컴투스 홀', '컴투스홀딩스')
total_nouns[i] = total_nouns[i].replace('개발 사', '개발사')
total_nouns[i] = total_nouns[i].replace('펄 어비스', '펄어비스')
total_nouns[i] = total_nouns[i].replace('콜 라보', '콜라보')
total_nouns[i] = total_nouns[i].replace('카 테 고리', '카테고리')
total_nouns[i] = total_nouns[i].replace('확률 형', '확률형')
total_nouns[i] = total_nouns[i].replace('역대 급', '역대급')
total_nouns[i] = total_nouns[i].replace('마비 노기', '마비노기')
total_nouns[i] = total_nouns[i].replace('게임 위', '게임위')
total_nouns[i] = total_nouns[i].replace('컬 래 버 레이 션', '콜라보레이션')
total_nouns[i] = total_nouns[i].replace('콜 라보 레이 션', '콜라보레이션')
total_nouns[i] = total_nouns[i].replace('빅 게임', '빅게임')
total_nouns[i] = total_nouns[i].replace('엔 씨', '엔씨')
total_nouns[i] = total_nouns[i].replace('스타트 업', '스타트업')
total_nouns[i] = total_nouns[i].replace('디바 이스', '디바이스')
total_nouns[i] = total_nouns[i].replace('선택 지', '선택지')
total_nouns[i] = total_nouns[i].replace('치지 직', '치지직')
total_nouns[i] = total_nouns[i].replace('어 플리 케이 션', '어플리케이션')
total_nouns[i] = total_nouns[i].replace('게임 쇼', '게임쇼')
total_nouns[i] = total_nouns[i].replace('아스 달', '아스달')
total_nouns[i] = total_nouns[i].replace('김실 장', '김실장')
total_nouns[i] = total_nouns[i].replace('행 안부', '행안부')
# 게임 뉴스이기 때문에 게임과 관련된 부분, 뉴스와 관련된 부분은 제거한다.
total_nouns[i] = total_nouns[i].replace('게임', '')
total_nouns[i] = total_nouns[i].replace('기자', '')
total_nouns[i] = total_nouns[i].replace('기사', '')
total_nouns[i] = total_nouns[i].replace('진행', '')
total_nouns[i] = total_nouns[i].replace('이용자', '')
total_nouns[i] = total_nouns[i].replace('플레이', '')
total_nouns[i] = total_nouns[i].replace('이번', '')
# 매일매일 기사에서 반복되는 단어들을 삭제한다.
# 의미가 없는 단어들은 아니지만, 지속적으로 나오면서 의미를 부여하기 어려운 단어가 되었다.
total_nouns[i] = total_nouns[i].replace('지난해', '')
total_nouns[i] = total_nouns[i].replace('전년', '')
total_nouns[i] = total_nouns[i].replace('콘텐츠', '')
total_nouns[i] = total_nouns[i].replace('출시', '')
total_nouns[i] = total_nouns[i].replace('서비스', '')
total_nouns[i] = total_nouns[i].replace('모바일', '')
total_nouns[i] = total_nouns[i].replace('제공', '')
total_nouns[i] = total_nouns[i].replace('예정', '')
# 단어가 두 글자 이상인 것만 토픽 모델링을 진행할 데이터에 넣어준다.
a = total_nouns[i].split(' ')
data = ''
for j in a :
if len(j) >= 2 :
# 동일한 이유로 띄어쓰기로 붙여 넣는다.
# 마찬가지로 줄바꿈으로 진행해도 된다.
data = data+' '+j
total_nouns[i] = data저는 total_nouns의 일부를 확인하고 진행을 하고 있기 때문에 여러분들은 여러분들의 데이터에 맞게 전처리를 진행하시면 됩니다!
- LDA 모델에 학습하기 알맞게 데이터 변형하기
데이터 전처리가 끝난 후에는 LDA 모델에 학습하기 알맞게 데이터를 변형해야 합니다.
데이터를 변형하는 코드는 아래와 같습니다.
# CountVectorizer 객체 생성
# CountVectorizer는 문서에서 단어의 빈도수를 계산하는 도구이다.
CV_vectorizer = CountVectorizer()
# total_nouns에 있는 단어의 빈도수를 행렬로 변경한다.
X = CV_vectorizer.fit_transform(total_nouns)
- LDA 모델 생성 및 데이터 학습
이제 데이터가 완성되었으니, LDA 모델을 만들어 데이터를 학습시키도록 하겠습니다!!
LDA 모델을 만드는 코드는 아래와 같습니다.
# 토픽의 개수를 지정한다.
num_topics = 6
# LDA 모델을 생성한다.
# 동일한 결과물을 얻기 위해서 random_state(난수)를 42로 고정한다.
lda = LatentDirichletAllocation(n_components=num_topics, random_state=42)
# 위에서 만든 데이터 X를 LDA 모델에 학습을 시킨다.
# 이제 lda는 데이터 X가 6개의 토픽으로 분류된 정보가 담겨있다.
lda.fit(X)- 각 토픽 내 주요 키워드 찾기
토픽으로 분류를 완료하였으니, 각 토픽이 어떤 키워드를 가지고 있는지 확인해보도록 하겠습니다.
저는 각 토픽마다 7개의 키워드를 추출해서 데이터 프레임을 새로 만들었습니다!
키워드의 수는 원하는대로 지정하시면 됩니다.
키워드를 추출하는 코드는 아래와 같습니다.
# CountVectorizer를 통해 추출된 단어의 목록을 얻는다.
# 단어의 목록은 array로 저장되어 있다.
CV_feature_names = CV_vectorizer.get_feature_names_out()
# 각 토픽의 키워드를 담을 리스트
# 여기에 초기화를 진행해주지 않으면, 다른 날짜의 기사를 진행할 때 진행이 잘 되지 않을 수 있다.
topic_keywords = []
# 토픽 수를 구분하는 변수
topic_index = 1
# 키워드 수를 구분하는 변수
# 키워드 수를 변경하고 싶다면, 숫자를 원하는 키워드 수로 변경하면 된다.
num_word = 7
# lda.components_가 이중 array로 되어 있기 때문에 데이터를 쉽게 다루기 위해수 enumerate로 데이터를 가져온다.
for topic_idx, topic in enumerate(lda.components_):
# topic에는 단어의 빈도 확률이 들어있기 때문에 가장 높은 빈도 확률 7개의 인덱스를 추출한다.
top_keywords_idx = topic.argsort()[::-1][:num_word]
# 단어 목록에서 빈도 확률과 동일한 인덱스를 가진 단어를 추출한다.
top_keywords = [CV_feature_names[i] for i in top_keywords_idx]
# 토픽을 구분하는 값을 맨 앞에 삽입해준다.
top_keywords.insert(0, 'Topic %d' %(topic_index))
topic_index = topic_index+1
topic_keywords.append(top_keywords)
# 추출한 7개의 키워드를 데이터 프레임으로 변경한다.
df_topic_keywords = pd.DataFrame(topic_keywords, columns=["Topic"]+ [f"Keyword {i+1}" for i in range(num_word)])이렇게 만들어진 df_topic_keywords의 결과물은 아래와 같습니다!
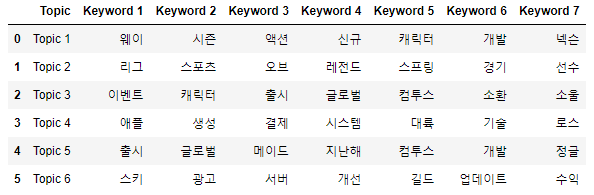
저는 6개의 토픽과 7개의 키워드로 진행을 했기 때문에 이런 결과가 나왔습니다.
실제 토픽의 수와 비슷할수록 정확하게 토픽을 구분하지만, 실제 토픽의 수를 알 수 없으니 다양하게 해보시길 바랍니다.
- 전체코드
import pandas as pd
from konlpy.tag import *
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
result = pd.read_excel('파일 이름')
Title = list(result['title'])
Information = list(result['information'])
Total = []
for i in range(len(result)) :
Total.append(Title[i]+' '+Information[i])
komoran = Komoran()
total_nouns = [' '.join(komoran.nouns(doc)) for doc in Total]
# 전처리 과정
for i in range(len(total_nouns)) :
total_nouns[i] = total_nouns[i].replace('위 메이드', '위메이드')
total_nouns[i] = total_nouns[i].replace('위 믹스', '위믹스')
total_nouns[i] = total_nouns[i].replace('컴투스 홀', '컴투스홀딩스')
total_nouns[i] = total_nouns[i].replace('개발 사', '개발사')
total_nouns[i] = total_nouns[i].replace('펄 어비스', '펄어비스')
total_nouns[i] = total_nouns[i].replace('콜 라보', '콜라보')
total_nouns[i] = total_nouns[i].replace('카 테 고리', '카테고리')
total_nouns[i] = total_nouns[i].replace('확률 형', '확률형')
total_nouns[i] = total_nouns[i].replace('역대 급', '역대급')
total_nouns[i] = total_nouns[i].replace('마비 노기', '마비노기')
total_nouns[i] = total_nouns[i].replace('게임 위', '게임위')
total_nouns[i] = total_nouns[i].replace('컬 래 버 레이 션', '콜라보레이션')
total_nouns[i] = total_nouns[i].replace('콜 라보 레이 션', '콜라보레이션')
total_nouns[i] = total_nouns[i].replace('빅 게임', '빅게임')
total_nouns[i] = total_nouns[i].replace('엔 씨', '엔씨')
total_nouns[i] = total_nouns[i].replace('스타트 업', '스타트업')
total_nouns[i] = total_nouns[i].replace('디바 이스', '디바이스')
total_nouns[i] = total_nouns[i].replace('선택 지', '선택지')
total_nouns[i] = total_nouns[i].replace('치지 직', '치지직')
total_nouns[i] = total_nouns[i].replace('어 플리 케이 션', '어플리케이션')
total_nouns[i] = total_nouns[i].replace('게임 쇼', '게임쇼')
total_nouns[i] = total_nouns[i].replace('아스 달', '아스달')
total_nouns[i] = total_nouns[i].replace('김실 장', '김실장')
total_nouns[i] = total_nouns[i].replace('행 안부', '행안부')
total_nouns[i] = total_nouns[i].replace('게임', '')
total_nouns[i] = total_nouns[i].replace('기자', '')
total_nouns[i] = total_nouns[i].replace('기사', '')
total_nouns[i] = total_nouns[i].replace('진행', '')
total_nouns[i] = total_nouns[i].replace('이용자', '')
total_nouns[i] = total_nouns[i].replace('플레이', '')
total_nouns[i] = total_nouns[i].replace('이번', '')
total_nouns[i] = total_nouns[i].replace('지난해', '')
total_nouns[i] = total_nouns[i].replace('전년', '')
total_nouns[i] = total_nouns[i].replace('콘텐츠', '')
total_nouns[i] = total_nouns[i].replace('출시', '')
total_nouns[i] = total_nouns[i].replace('서비스', '')
total_nouns[i] = total_nouns[i].replace('모바일', '')
total_nouns[i] = total_nouns[i].replace('제공', '')
total_nouns[i] = total_nouns[i].replace('예정', '')
a = total_nouns[i].split(' ')
data = ''
for j in a :
if len(j) >= 2 :
data = data+' '+j
total_nouns[i] = data
CV_vectorizer = CountVectorizer()
X = CV_vectorizer.fit_transform(total_nouns)
num_topics = 6
lda = LatentDirichletAllocation(n_components=num_topics, random_state=42)
lda.fit(X)
CV_feature_names = CV_vectorizer.get_feature_names_out()
topic_keywords = []
topic_index = 1
num_word = 7
for topic_idx, topic in enumerate(lda.components_):
top_keywords_idx = topic.argsort()[::-1][:num_word]
top_keywords = [CV_feature_names[i] for i in top_keywords_idx]
top_keywords.insert(0, 'Topic %d' %(topic_index))
topic_index = topic_index+1
topic_keywords.append(top_keywords)
df_topic_keywords = pd.DataFrame(topic_keywords, columns=["Topic"]+ [f"Keyword {i+1}" for i in range(num_word)])- 활용하기
제가 개인적으로 토픽 모델링과 다른 시각화를 활용하여 네이버 기사를 분석한 예시입니다.

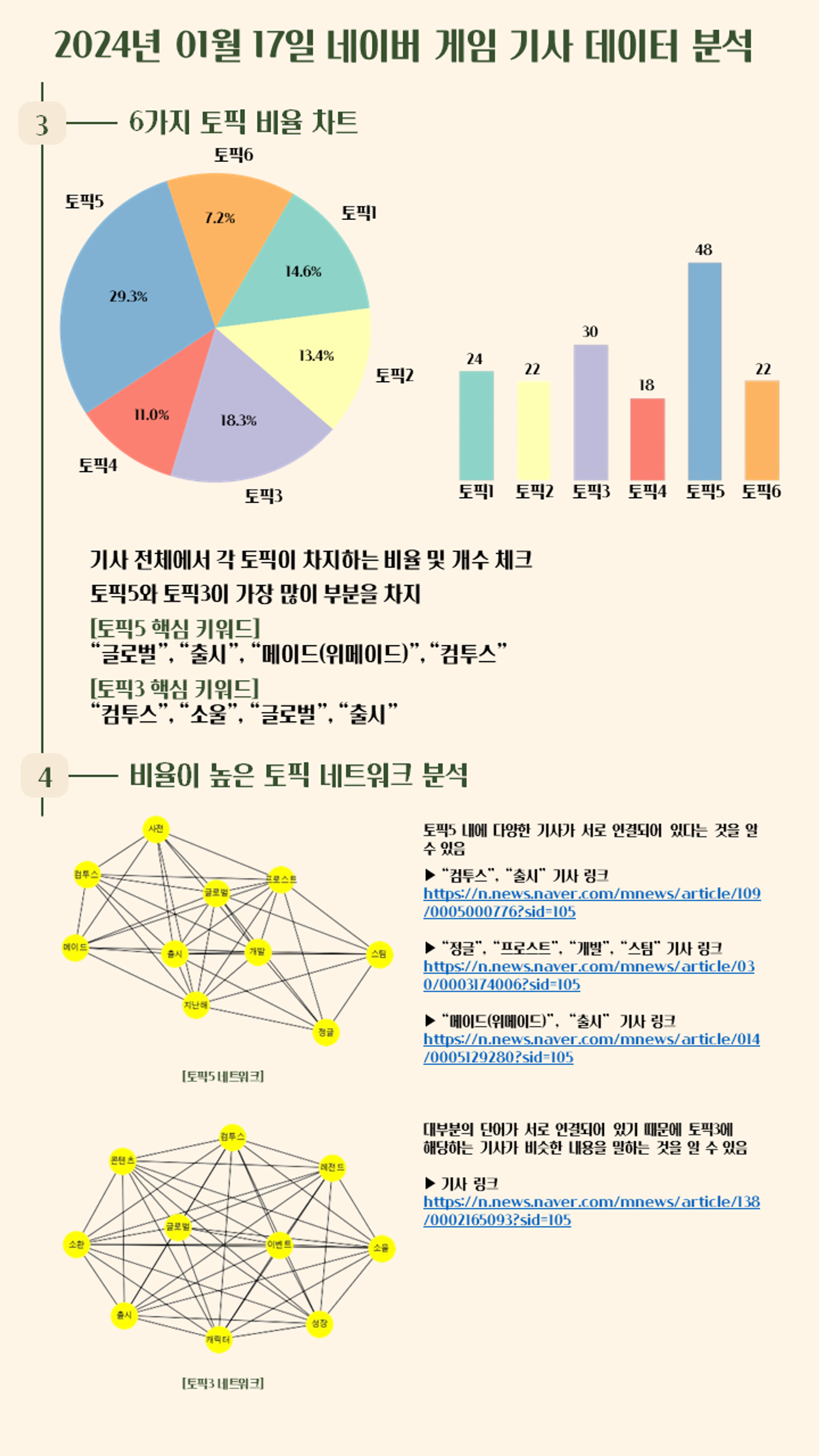
예시에서 활용한 파이 차트 및 바 차트, 네트워트 분석은 다음 포스팅에서 진행하겠습니다!!
한글 데이터로 워드클라우드를 만드는 방법이 궁금하신 분들은 아래 링크를 확인해주세요:)
[데이터 분석] 한글로 워드클라우드 만들기 (feat.네이버 뉴스 크롤링)
안녕하세요. 오늘은 크롤링 데이터로 워드클라우드(wordcloud)를 만드는 방법에 대해 포스팅 하겠습니다. 크롤링 데이터는 네이버 뉴스 크롤링을 사용할 예정입니다! 네이버 뉴스 크롤링 과정이
yhj9855.com
코드에 대해 궁금한 부분이 있으신 분들은 댓글로 남겨주시면, 답변 드리도록 하겠습니다.

★읽어주셔서 감사합니다★
'Python(파이썬) > Data Analysis(데이터 분석)' 카테고리의 다른 글
| [데이터 분석] 한글로 워드클라우드 만들기 (feat.네이버 뉴스 크롤링) (72) | 2024.01.25 |
|---|