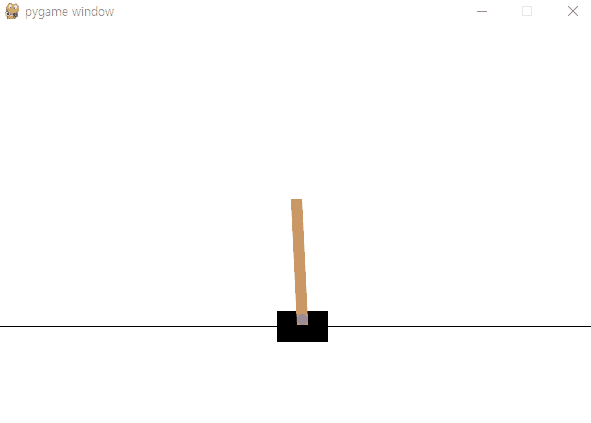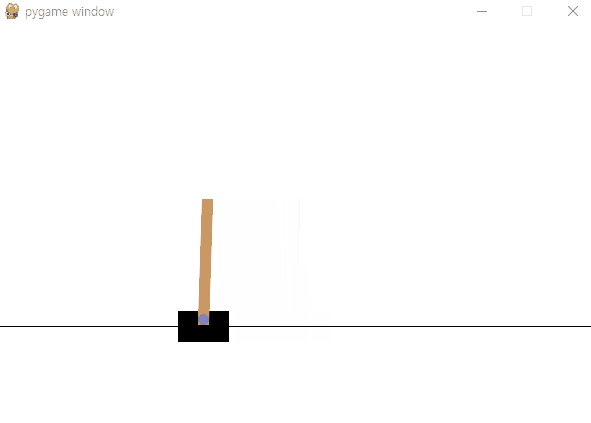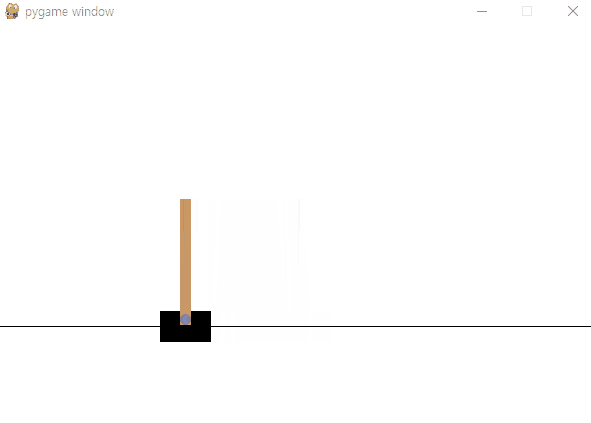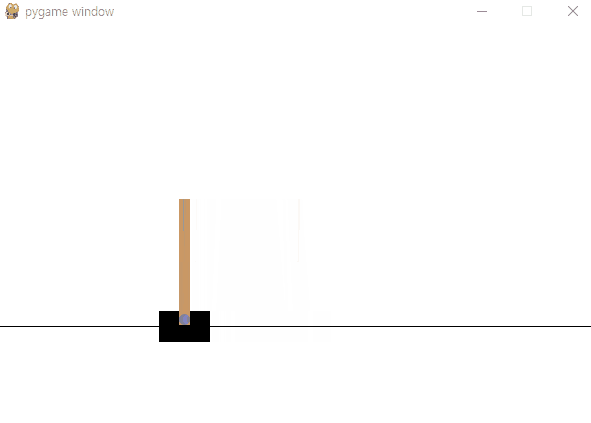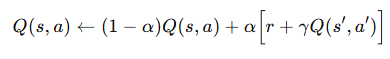import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성
x = np.linspace(0, 10, 100)
y = np.sin(x)
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.title("Title")
plt.plot(x, y)
위치 변경하기
x축, y축, 제목은 모두 위치를 변경할 수 있습니다.
위치는 두 가지 방법으로 옮길 수 있습니다.
1. pad를 사용하여 간격을 조절
import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성
x = np.linspace(0, 10, 100)
y = np.sin(x)
plt.xlabel("X-axis", labelpad=40)
plt.ylabel("Y-axis", labelpad= 30)
plt.title("Title", pad=30)
plt.plot(x, y)
각 축과 제목의 간격이 멀어지신게 보이시나요?
pad 내 숫자가 커질수록 그래프와 축/제목 사이의 간격을 멀게 설정할 수 있습니다.
ㄴ
2. 좌표를 설정하여 위치를 조절
제목은 좌표를 설정해서 위치를 조절할 수 있습니다!
축의 경우에도 동일하게 좌표 설정을 할 수 있는데, 좌표대로 잘 움직이지 않아 거의 사용하지 않습니다ㅠㅠ
import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성
x = np.linspace(0, 10, 100)
y = np.sin(x)
fig, ax = plt.subplots(figsize=(6, 4))
# 글씨 크기 조절 가능
plt.xlabel("X-axis", fontsize=14)
plt.ylabel("Y-axis", fontsize=14)
ax.set_title("Title", fontsize=14, x=0.8, y=1.05)
plt.plot(x, y)
제목의 위치가 변경되신게 보이시나요?
x는 좌우의 위치를, y는 상하의 위치를 변경할 수 있습니다!
범례 설정하기
범례란?
범례는 지도나 차트 등에서 참고하라는 뜻으로 나타낸 정보입니다.
파이썬 시각화에서는 보통 각 그래프가 어떤 것을 나타내는지 표기할 때 많이 사용합니다!
아래 그래프처럼 노란색과 연두색이 각각 어떤 그래프를 나타내는지 아래쪽에 표기된 것이 범례입니다.
범례 생성하기
보통 범례는 자동으로 생성되는 경우가 많은데, 그래프를 각각 그릴 경우에는 범례가 생성되지 않습니다.
이 때 직접 범례를 설정하는 것도 가능합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 생성
x = np.linspace(0, 10, 100)
y = np.cos(x)
y1 = np.sin(x)
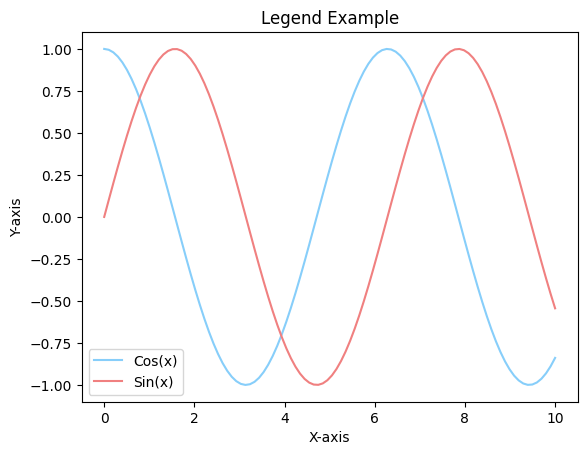
line1, = plt.plot(x, y, color='lightskyblue')
line2, = plt.plot(x, y1, color='lightcoral')
# 범례 직접 설정
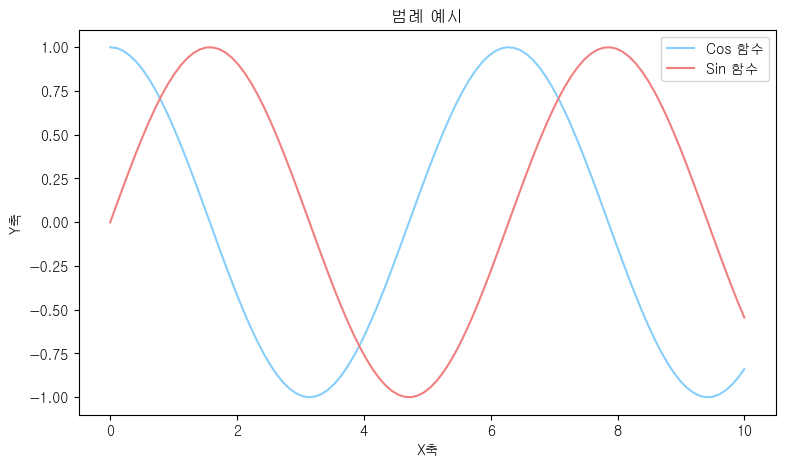
plt.legend(handles=[line1, line2], labels=["Cos(x)", "Sin(x)"])
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.title("Legend Example")
plt.show()
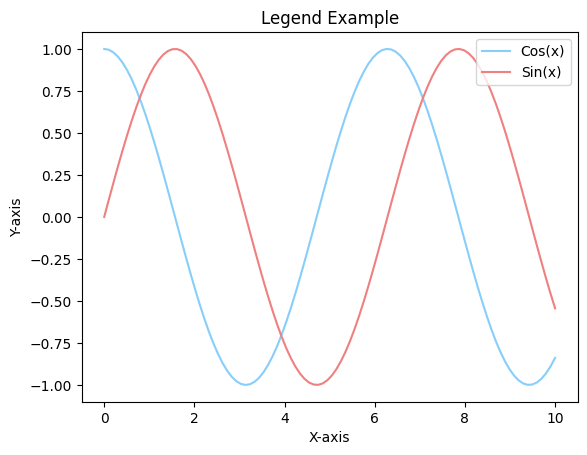
plt.legend(handles=[line1, line2], labels=["Cos(x)", "Sin(x)"]) 여기서 loc = 옵션을 추가하게 되면 범례의 위치를 어느 정도 조정할 수 있습니다!
예를 들어 upper right 옵션으로 하게 되면, 오른쪽 위에 범례가 생성되는데요, 옵션을 정하지 않으면 가장 적당한 위치에 알아서 생성이 됩니다.
ㄷ
위치 변경하기
위의 사진처럼 범례가 자동으로 생성될 때 그래프를 가리는 경우를 자주 접하실 수 있는데요!
이 때 범례 위치를 변경하는 코드는 알아두시면 유용합니다:)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 생성
x = np.linspace(0, 10, 100)
y = np.cos(x)
y1 = np.sin(x)
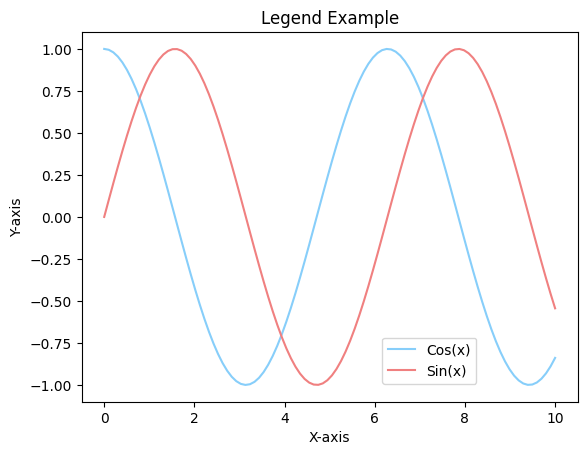
line1, = plt.plot(x, y, color='lightskyblue')
line2, = plt.plot(x, y1, color='lightcoral')
# 범례 직접 설정
plt.legend(handles=[line1, line2], labels=["Cos(x)", "Sin(x)"], loc='lower right', bbox_to_anchor=(0.81, 0.03))
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.title("Legend Example")
plt.show()
범례의 위치가 변경된 게 보이시나요?
지금은 예쁘게 옮긴 건 아니지만, 범례를 자유롭게 움직일 수 있는 것은 굉장히 편리하니 잘 사용해주세요!
먼저 loc 옵션을 조정하여 큰 틀의 위치를 정해주시고, bbox_to_anchor 내 좌표로 세세한 위치를 조정해주시면 됩니다:)
한글 설정하기
마지막으로 각 축, 제목, 범례를 한글로 정하는 방법에 대해서 알려드리겠습니다!
보통 한글로 설정을 하게 되면 아래 사진처럼 한글이 깨져서 나오기 때문에 한글 설정이 먼저 필요합니다.
한글 설정을 위해서는 먼저 한글 폰트를 찾아야 합니다.
C:\Windows\Fonts 해당 경로로 가시면, 컴퓨터에 설치되어 있는 폰트를 보실 수 있습니다!
이제 저희가 사용하고 싶은 폰트를 고르면 되는데, 아쉽게도 모든 폰트를 지원하지는 않습니다ㅠㅠ
파이썬은 바탕, 굴림, 궁서체 중 골라서 사용하시는게 안전합니다:) (그래도 이것저것 해보시는 걸 추천 드려요)
위의 글씨체 중 하나를 골라 마우스 오른쪽 클릭→속성→이름 복사를 하시면 되는데, 이름은 .ttc 앞까지만 복사해주세요!
※ 만약에 속성이 나타나지 않는다면, 폰트를 더블 클릭해서 들어가신 다음 진행하시면 됩니다.
간혹 HY시리즈는 이름 그대로를 사용하셔야 되는 경우도 있습니다.
예를 들면 HYPost의 경우 HYPost-Medium, HY고딕의 경우 HYGothic-Medium을 사용합니다.
ㄹ
이제 아래 코드를 실행하시게 되면 한글 지원이 가능합니다.
plt.rcParams['font.family'] = 'HYPost-Medium'
이제 한글로 잘 보이는 걸 알 수 있습니다!!
하지만 한글로 변경할 때는 종종 숫자의 마이너스가 깨지는 경우가 있어요ㅠㅠ
해당 경우는 마이너스가 지원되는 한글을 써야하는데, 저는 보통 굴림을 사용합니다.
plt.rcParams['font.family'] = 'gulim'
이제 한글과 마이너스가 모두 잘 보이는 것을 확인할 수 있습니다!
여기까지 축, 제목, 범례 활용을 정리해보았습니다!
이것저것 쓰다보니 꽤 길어졌는데요, 시각화는 예쁘면 예쁠수록 도움이 되기 때문에 세세한 부분이라도 잘 활용하시면 좋을 것 같습니다:)
특히 한글 설정 같은 경우, 글씨체가 이쁘면 보기도 좋으니 여러 폰트로 한 번 사용해보시길 추천드려요ദ്ദി・ᴗ・)✧
안녕하세요! 오늘은 파이썬으로 하는 시각화 활용 Line plot에 대해 포스팅 하려고 합니다.
Line plot이란?
시간이나 연속적인 값을 나타낼 때 사용되는 그래프로, 일반적인 선 그래프 입니다.
보통 x축에는 연속적인 변수를 y축에는 수치형 데이터를 배치해서 사용하는 경우가 일반적입니다.
저는 보통 식을 그릴 때는 matplotlib, 데이터 프레임이 있는 경우에는 seaborn, matplotlib 두 개를 함께 사용해서 line plot을 그립니다.
matplotlib로 단일 그래프 그리기
우선 먼저 matplotlib를 사용해서 간단한 그래프를 그려보겠습니다.
아래처럼 숫자를 직접 입력하거나, 특정 식이 존재한다면 matplotlib만 사용해서 그리는 것이 간단합니다!
import matplotlib.pyplot as plt
# 왼쪽이 x 값, 오른쪽이 y 값
plt.plot([1, 2, 3, 4], [2, 3, 5, 10])
plt.show()
import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성
x = np.linspace(0, 10, 100)
y = np.sin(x)
plt.plot(x, y)
plt.show()
seaborn을 함께 사용하여 단일 그래프 그리기
seaborn은 데이터 프레임과 호환성이 좋기 때문에 보통 데이터 프레임으로 사용합니다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 생성
x = np.linspace(0, 10, 100)
y = np.cos(x)
df = pd.DataFrame({"X": x, "Y": y})
sns.lineplot(x="X", y="Y", data=df)
그래프 커스텀 하기
사실 그래프를 그리는 것은 정말 간단합니다!
하지만 그래프를 단순히 그리는 것과 이를 커스텀해서 사용하는 것은 정말 큰 차이가 있습니다.
학습이 진행 중인policy_net에서 행동을 선택할 경우,학습이 불안정할 가능성이 높아 target_net에서 진행하는 것이 더 좋습니다.
2. 확률로 행동 선택하기
해당 방법은Q값을 확률로 변경한 다음,확률대로 행동을 선택하게 하는 것을 의미합니다.
이 방법을 사용할 경우, 확률적으로 행동을 선택하기 때문에어느 정도 학습이 진행되어도 탐험을 보장한다는 것과 ϵ을 따로 세팅해주지 않아도 되는 것이 장점이라고 볼 수 있습니다!
확률로 행동을 선택하는 코드는 아래와 같습니다.
defselect_action(state, target_net, action_dim):
q_value = target_net(state)
# Q 값을 확률 값으로 바꾸는 과정
p = F.softmax(q_value, dim=0).tolist()
# 부동소수점 오차로 인해 합이 1이 안되는 문제 해결
p = np.array(p)
p /= p.sum()
action = np.random.choice(action_dim, p=p)
return action
DDQN 공식을 사용해서 업데이트
이제 DDQN 공식을 사용해서 네트워크를 업데이트 하는 것을 구현해보도록 하겠습니다.
코드로 들어가지 전에 먼저DDQN 공식을 먼저 살펴보겠습니다.
기본적으로는 DQN과 비슷한 공식입니다!
DQN과 Q가 두 번 사용된 것을 보실 수 있습니다.
DQN과 마찬가지로 DDQN은 딥러닝을 사용하기 때문에 자체적으로옵티마이저와 learning rate가 들어가게 됩니다.
이두 개가 DDQN의 α로 작용을 하기 때문에 실제로 사용하는공식에는 α가 사라져아래와 같은 공식이 됩니다!
학습이 진행 중인 policy_net에서 행동을 선택할 경우, 학습이 불안정할 가능성이 높아 target_net에서 진행하는 것이 더 좋습니다.
2. 확률로 행동 선택하기
해당 방법은 Q값을 확률로 변경한 다음, 확률대로 행동을 선택하게 하는 것을 의미합니다.
이 방법을 사용할 경우, 확률적으로 행동을 선택하기 때문에 어느 정도 학습이 진행되어도 탐험을 보장한다는 것과 ϵ을 따로 세팅해주지 않아도 되는 것이 장점이라고 볼 수 있습니다!
확률로 행동을 선택하는 코드는 아래와 같습니다.
defselect_action(state, target_net, action_dim):
q_value = target_net(state)
# Q 값을 확률 값으로 바꾸는 과정
p = F.softmax(q_value, dim=0).tolist()
# 부동소수점 오차로 인해 합이 1이 안되는 문제 해결
p = np.array(p)
p /= p.sum()
action = np.random.choice(action_dim, p=p)
return action
DQN 공식을 사용해서 업데이트
이제 DQN 공식을 사용해서 네트워크를 업데이트 하는 것을 구현해보도록 하겠습니다.
코드로 들어가지 전에 먼저 DQN 공식을 먼저 살펴보겠습니다.
기본적으로는 Q-learning과 동일한 공식입니다!
하지만 DQN은 딥러닝을 사용하기 때문에 자체적으로 옵티마이저와 learning rate가 들어가게 됩니다.
이 두 개가 DQN의 α로 작용을 하기 때문에 실제로 사용하는 공식에는 α가 사라져 아래와 같은 공식이 됩니다!
θ ̄ 는 α 대신 네트워크가 작동하는 부분이라고 생각하시면 됩니다.
α를 사용하지 않기 때문에 일종의 TD 으로도 보실 수 있는데요.
TD 공식으로 변형해서 사용하셔도 문제 없이 학습하실 수 있습니다:)
이제 해당 공식을 바탕으로 DQN을 진행하는 코드는 아래와 같습니다.
defoptimize_model(memory, policy_net, target_net, optimizer):# batch_size만큼 데이터가 메모리에 쌓였을 때만 학습 진행iflen(memory) < batch_size:
return# transitions = (state, action, reward, next_state, done)
transitions = memory.sample(batch_size)
# state, action, reward, next_state, done을 각각 묶어서 list의 형태로 만드는 작업
batch = list(zip(*transitions))
state_batch = torch.stack(batch[0])
action_batch = torch.tensor(batch[1]).unsqueeze(1)
reward_batch = torch.tensor(batch[2])
next_state_batch = torch.stack(batch[3])
done_batch = torch.tensor(batch[4], dtype=torch.float32)
# DQN
q_values = policy_net(state_batch).gather(1, action_batch)
next_q_values = target_net(next_state_batch).max(1)[0].detach()
# (1-done_batch)을 통해 에피소드가 끝났는지 아닌지를 판단
target_q_values = reward_batch + (gamma * next_q_values * (1-done_batch))
loss = nn.MSELoss()(q_values.squeeze(), target_q_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
q_values를 policy_net에서 가져오는 이유는 학습 중인 policy_net과 DQN 공식을 적용한 target_net가 비슷해지도록 학습이 되야 하기 때문입니다.
모델 학습
이제 본격적으로 학습을 진행해보도록 하겠습니다.
한 가지 중요한 점은 Cart Pole 환경이 500점을 달성해도, 에피소드 완료라고 판단하지 않기 때문에 저희가 직접 판단해줘야 합니다.
학습을 진행하는 코드는 아래와 같습니다.
# 초기 세팅
policy_net = DQN(state_dim, action_dim)
target_net = DQN(state_dim, action_dim)
target_net.load_state_dict(policy_net.state_dict())
target_net.eval()
optimizer = optim.Adam(policy_net.parameters(), lr=learning_rate)
memory = ReplayMemory(memory_size)
# epsilon-greedy 방법으로 행동을 선택할 때 필요# epsilon = epsilon_start
episode_rewards = []
episode_reward = 0
save_dir = "dqn_saved_models"
os.makedirs(save_dir, exist_ok=True)
# 모델 학습for episode inrange(episodes):
state = torch.tensor(env.reset()[0], dtype=torch.float32)
if episode % 1000 == 0:
print(f"Episode {episode}, Avg Reward: {episode_reward/1000}")
if episode % 1000 == 0 :
episode_reward = 0
total_reward = 0# 500 초과인 경우는 done으로 판단while total_reward < 501 :
action = select_action(state, target_net, action_dim)
next_state, reward, done, _, _ = env.step(action)
next_state = torch.tensor(next_state, dtype=torch.float32)
memory.push((state, action, reward, next_state, done))
state = next_state
total_reward += reward
optimize_model(memory, policy_net, target_net, optimizer)
if done :
break# 500점 달성한 모델 저장if total_reward >= 500 :
model_path = os.path.join(save_dir, f"dqn_model_episode_{episode}.pth")
torch.save(policy_net.state_dict(), model_path)
episode_reward += total_reward
# epsilon-greedy로 action을 선택할 때는 있어야 함# if episode % 10 == 0 :# epsilon = max(epsilon_end, epsilon*epsilon_decay)if episode % 20 == 0:
target_net.load_state_dict(policy_net.state_dict())
episode_rewards.append(total_reward)
리워드 시각화 및 모델 테스트
마지막으로 저희가 학습한 모델이 잘 학습되었는지 확인하기 위해, 리워드를 시각화하고 모델을 테스트해보겠습니다.
먼저 리워드 시각화 하는 코드는 아래와 같습니다.
plt.plot(episode_rewards)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('DQN on CartPole')
plt.show()
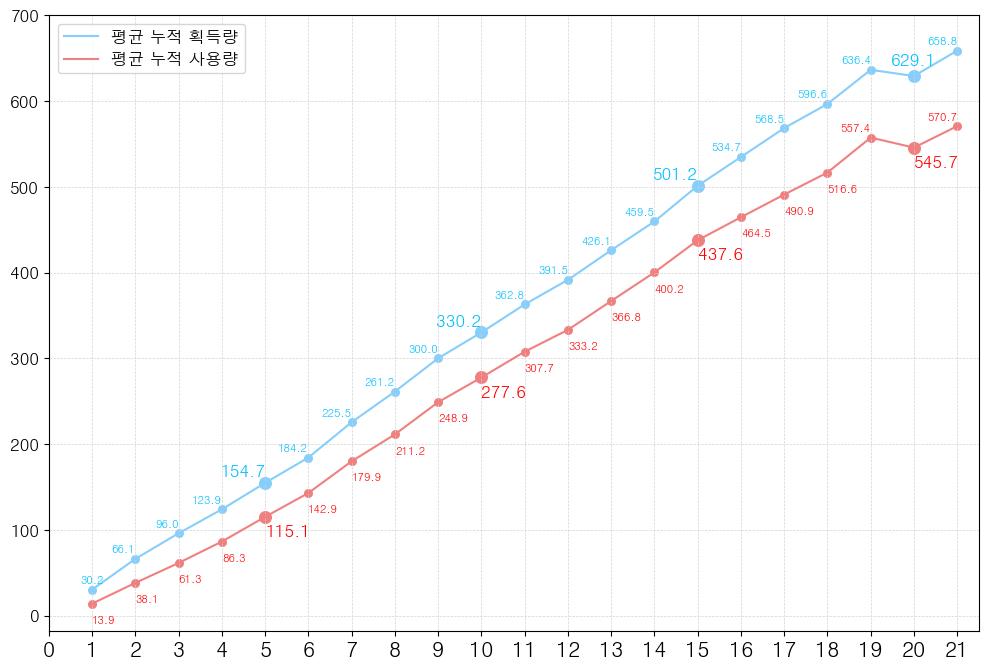
저는 위와 같은 결과 값이 나왔는데요, 한결 같은 값을 가지는 것은 아니지만 전체적으로 점점 리워드가 상승하는 것을 볼 수 있습니다.
이처럼 여러분의 리워드도 전체적으로 상승하는 형상을 보이고 있다면, 학습이 잘 된 것으로 보실 수 있습니다.
다음은 모델 테스트를 진행해보겠습니다.
저는 모든 모델을 테스트 한 것은 아니도, 500점 이상을 달성한 모델만 따로 저장하여 모델 테스트를 진행해보았습니다.
리워드 그래프에서도 보셨듯, 전체적으로 리워드가 상승하는 것이지 모든 모델이 좋은 모델이라고는 볼 수 없기 때문에 최대치의 리워드를 달성한 모델로 테스트를 진행하였어요!
모델 테스트를 진행하는 코드는 아래와 같습니다.
# 테스트 시, render 활성화 필요
env = gym.make("CartPole-v1", render_mode='human')
# 500 달성한 모델 업로드
model_paths = glob.glob(os.path.join(save_dir, "*.pth"))
model_i = 0for model_path in model_paths :
policy_net.load_state_dict(torch.load(model_path))
policy_net.eval()
avg_reward = 0# 각 모델 별 10번 진행for episode inrange(10) :
state = torch.tensor(env.reset()[0], dtype=torch.float32)
total_reward = 0while total_reward < 501 :
with torch.no_grad() :
action = policy_net(state).argmax().item()
next_state, reward, done, _, _ = env.step(action)
next_state = torch.tensor(next_state, dtype=torch.float32)
state = next_state
total_reward += reward
if done :
break
avg_reward += total_reward
print(f"model {model_i + 1}, Avg Reward: {avg_reward/10}")
model_i += 1
특정 모델은 500점 리워드를 달성하지 못하는 경우도 있었지만, 대부분은 500점 이상을 달성하는 것을 볼 수 있었습니다.
모델마다 다른 방식으로 500점을 달성하는데, 한 번 구경해보시는 것도 좋을 것 같아요!
전체 코드
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
import random
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
import os
import glob
import torch.nn.functional as F
# 하이퍼 파라미터
gamma = 0.99
learning_rate = 0.0005
batch_size = 100
memory_size = 5000
episodes = 5000# ϵ-greedy 사용 시, 필요# epsilon_start = 1.0# epsilon_end = 0.001# epsilon_decay = 0.995classDQN(nn.Module):def__init__(self, state_dim, action_dim):super(DQN, self).__init__()
self.fc1 = nn.Linear(state_dim, 32)
self.fc2 = nn.Linear(32, 32)
self.fc3 = nn.Linear(32, action_dim)
defforward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
classReplayMemory:def__init__(self, capacity):
self.memory = deque(maxlen=capacity)
defpush(self, transition):
self.memory.append(transition)
defsample(self, batch_size):return random.sample(self.memory, batch_size)
def__len__(self):returnlen(self.memory)
defselect_action(state, target_net, action_dim):# ϵ-greedy# if random.random() < epsilon:# return random.randint(0, action_dim - 1)# else:# return target_net(state).argmax().item()
q_value = target_net(state)
p = F.softmax(q_value, dim=0).tolist()
p = np.array(p)
p /= p.sum()
action = np.random.choice(action_dim, p=p)
return action
defoptimize_model(memory, policy_net, target_net, optimizer):iflen(memory) < batch_size:
return
transitions = memory.sample(batch_size)
batch = list(zip(*transitions))
state_batch = torch.stack(batch[0])
action_batch = torch.tensor(batch[1]).unsqueeze(1)
reward_batch = torch.tensor(batch[2])
next_state_batch = torch.stack(batch[3])
done_batch = torch.tensor(batch[4], dtype=torch.float32)
q_values = policy_net(state_batch).gather(1, action_batch)
next_q_values = target_net(next_state_batch).max(1)[0].detach()
# DQN
target_q_values = reward_batch + (gamma * next_q_values * (1 - done_batch))
loss = nn.MSELoss()(q_values.squeeze(), target_q_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
policy_net = DQN(state_dim, action_dim)
target_net = DQN(state_dim, action_dim)
target_net.load_state_dict(policy_net.state_dict())
target_net.eval()
optimizer = optim.Adam(policy_net.parameters(), lr=learning_rate)
memory = ReplayMemory(memory_size)
# epsilon = epsilon_start
episode_rewards = []
episode_reward = 0
save_dir = "dqn_saved_models"
os.makedirs(save_dir, exist_ok=True)
for episode inrange(episodes):
state = torch.tensor(env.reset()[0], dtype=torch.float32)
if episode % 100 == 0:
print(f"Episode {episode}, Avg Reward: {episode_reward/100}")
if episode % 100 == 0 :
episode_reward = 0
total_reward = 0# 500 초과인 경우는 done으로 판단while total_reward < 501 :
action = select_action(state, target_net, action_dim)
next_state, reward, done, _, _ = env.step(action)
next_state = torch.tensor(next_state, dtype=torch.float32)
memory.push((state, action, reward, next_state, done))
state = next_state
total_reward += reward
optimize_model(memory, policy_net, target_net, optimizer)
if done :
break# 500점 달성한 모델 저장if total_reward >= 500 :
model_path = os.path.join(save_dir, f"dqn_model_episode_{episode}.pth")
torch.save(policy_net.state_dict(), model_path)
episode_reward += total_reward
# ϵ-greedy 사용 시, 필요# if episode % 10 == 0 :# epsilon = max(epsilon_end, epsilon*epsilon_decay)if episode % 20 == 0:
target_net.load_state_dict(policy_net.state_dict())
episode_rewards.append(total_reward)
plt.plot(episode_rewards)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('DQN on CartPole')
plt.show()
# 테스트 진행
env = gym.make("CartPole-v1", render_mode='human')
# 500 달성한 모델 업로드
model_paths = glob.glob(os.path.join(save_dir, "*.pth"))
model_i = 0for model_path in model_paths :
policy_net.load_state_dict(torch.load(model_path))
policy_net.eval()
avg_reward = 0# 각 모델 별 10번 진행for episode inrange(10) :
state = torch.tensor(env.reset()[0], dtype=torch.float32)
total_reward = 0while total_reward < 501 :
with torch.no_grad() :
action = policy_net(state).argmax().item()
next_state, reward, done, _, _ = env.step(action)
next_state = torch.tensor(next_state, dtype=torch.float32)
state = next_state
total_reward += reward
if done :
break
avg_reward += total_reward
print(f"model {model_i + 1}, Avg Reward: {avg_reward/10}")
model_i += 1
딥러닝+강화학습으로 진행되기 때문에 모델 학습이나 이런 부분이 진행하면서 많이 어려웠습니다.
저도 이거 풀면서 딥러닝에 대한 지식이 부족하다는 것을 깨닫고 요즘은 딥러닝을 공부하고 있는데, 쉽지 않네요ㅠㅠ
DQN이랑 비슷한 DDQN으로 cart pole 문제를 푸는 방법은 아래 링크를 참고해주세요.
Q 값이 제대로 업데이트가 될 때까지충분한 탐험을 진행하지 못했을 경우, 제대로 된 행동을 추출할 수 없다는 것입니다.
예를 들어,초반에는 Q 값이 모두 0이기 때문에(0, 0)에서왼쪽으로 가는 행동만 선택하기 때문에 게임을 진행할 수가 없습니다.
저희는 이 문제를 해결하기 위해,ϵ-greedy방법을 사용할 수 있습니다.
ϵ-greedy란?
탐험과 이용의 균형을 맞추기 위한 행동 선택 방법으로, 아래 공식을 따릅니다.
여기서 ϵ은 0과 1 사이의 값으로ϵ 확률만큼은랜덤하게 행동을 하게 하여탐험을 진행하도록 하고,(1-ϵ)확률 만큼Q 값이 가장 높은 행동을 선택하도록 합니다.
해당 ϵ을 초반에 높게 설정하고 점차 ϵ을 줄임으로써,초반에는 랜덤 행동을 통한 탐험을 하게 하고 점차 Q 값을 이용하도록 행동을 선택할 수 있습니다.
ϵ-greedy를 활용하여 행동을 선택하는 코드는 아래와 같습니다.
# 초기 값은 보통 1로 설정
epsilon = 1.0
train = True# ϵ-greedy를 활용한 행동 선택defselect_action(state) :# 훈련을 할 경우에는 ϵ-greedy 방법을 사용# 테스트를 진행할 때는 온전히 Q 값만 사용# np.random.rand()를 넣어, 후반에도 종종 탐험을 할 수 있도록 함if np.random.rand() < epsilon and train :
action = np.random.choice([0, 1, 2, 3])
else :
action = np.argmax(Q[state])
return action
선택한 행동을 SARSA 공식을 사용해서 Q 값 업데이트
해당 부분은 위에서선택한 행동을 환경에서 실행해보고, 그결과 값을 SARSA 공식에 맞게 Q 값을 업데이트하는 것입니다.
코드로 들어가기 전에 먼저Q 테이블을 업데이트하는 공식을 먼저 살펴보겠습니다.
해당 수식은 Q(s, a)를 업데이트 하는데, 특정 학습률 α에 있어(1- α)만큼 현재의 Q 값과α만큼의 (보상값 r + 할인율 γ * 다음 state와 action의 Q값 Q(s', a'))를 반영한다는 의미입니다.
Q-learning을 배우신 분들은 아시겠지만, Q-learning에서의 maxQ값이 특정 행동 a'의 Q 값인 Q(s', a')로 바뀐 것을 알 수 있습니다.
학습률 α
값이 높을수록다음 행동 값 즉,새로운 정보를 더 많이 반영한다는 것이고,낮을수록현재의 Q 값 즉,기존의 경험을 더 많이 유지한다는 의미입니다.
할인율 γ
미래 보상의 중요도를 나타내는 지표로, 보통은 미래의 보상에 너무 의존하지 않도록1보다 약간 작은 수로 지정하는 것이 보통입니다.
Q(s', a')
실제로 선택한 다음 행동 a'에 대한 Q 값으로, 위의 행동 선택을 기반하여 다음 state에서 실제 action을 고른 값입니다.
이렇게 실제 행동을 기반으로 Q 값을 업데이트 하기 때문에, 안정적이지만 그만큼 느릴 수 있습니다.
하지만, frozen lake는 공간이 작은 문제라서 Q-learning과 크게 결과 차이는 없으실 거예요:)
해당 공식을 바탕으로 SARSA를 진행하는 코드는 아래와 같습니다.
# 학습을 진행할 때는 render 모드 비활성화
env = gym.make('FrozenLake-v1', desc=None, map_name=map_size, is_slippery=is_slippery)
env.reset()
# 환경의 행동 범위 : 여기서는 상, 하, 좌, 우 총 4개
action_size = env.action_space.n
# defaultdict은 키가 없을 때 자동으로 기본값을 생성하기 때문에 강화 학습에서 많이 사용
Q = defaultdict(lambda: np.zeros(action_size))
alpha = 0.1
gamma = 0.99# 총 학습을 진행할 에피소드 수
max_episode = 10000deflearn() :
reward_list = []
for i inrange(1, max_episode+1) :
# 100번째 마다 학습이 진행되고 있음을 출력if i % 100 == 0 :
# 해당 에피소드까지 진행된 모든 보상의 평균을 구함
avg_reward = sum(reward_list)/100print("\rEpisode {}/{} || average reward {}".format(i, max_episode, avg_reward), end="")
reward_list = []
# 에피소드를 처음 시작할 때 reset
state, _ = env.reset()
done = False
all_reward = 0# 에피소드가 종료될 때까지 반복whilenot done :
# Q 테이블을 바탕으로 action을 고르는 함수
action = select_action(state)
# state, reward, done 외 사용하지 않기 때문에 _ 처리
new_state, reward, done, _, _ = env.step(action)
next_action = select_action(new_state)
# SARSA
Q[state][action] = (1-alpha)*Q[state][action] + alpha*(reward + gamma*Q[new_state][next_action])
all_reward += reward
state = new_state
# 50번째 에피소드 마다 ϵ 값을 줄여줌if i % 50 == 0 :
epsilon *= 0.99
reward_list.append(all_reward)
위의 두 가지 과정을 합치면 SARSA로 frozen lake를 풀 수 있는 코드가 완성됩니다!
학습 후테스트를 진행하고 싶으신 경우에는render를 킨 환경을 다시 세팅해서 해주시면 됩니다.
전체 코드
행동 선택, 학습, 테스트 과정을 모두 포함한 전체 코드는 아래와 같습니다.
import gymnasium as gym
from collections import defaultdict
import numpy as np
# 미끄러짐 옵션 True/False 선택 가능
is_slippery = True# 8x8 중에 선택 가능
map_size = '4x4'
env = gym.make('FrozenLake-v1', desc=None, map_name=map_size, is_slippery=is_slippery)
env.reset()
action_size = env.action_space.n
Q = defaultdict(lambda: np.zeros(action_size))
alpha = 0.1
gamma = 0.99
epsilon = 1.0
train = True
max_episode = 100000defselect_action(state) :if np.random.rand() < epsilon and train :
action = np.random.choice([0, 1, 2, 3])
else :
action = np.argmax(Q[state])
return action
deflearn() :global epsilon
reward_list = []
for i inrange(1, max_episode+1) :
# 100번째 마다 학습이 진행되고 있음을 출력if i % 100 == 0 :
# 해당 에피소드까지 진행된 모든 보상의 평균을 구함
avg_reward = sum(reward_list)/100print("\rEpisode {}/{} || average reward {}".format(i, max_episode, avg_reward), end="")
reward_list = []
state, _ = env.reset()
done = False
all_reward = 0whilenot done :
action = select_action(state)
new_state, reward, done, _, _ = env.step(action)
next_action = select_action(new_state)
# SARSA
Q[state][action] = (1-alpha)*Q[state][action] + alpha*(reward + gamma*Q[new_state][next_action])
all_reward += reward
state = new_state
if i % 50 == 0 :
epsilon *= 0.99
reward_list.append(all_reward)
# 학습한 Q를 바탕으로 frozen lake 테스트deftesting_after_learning():# render를 켜야 제대로 학습이 되었는지 확인할 수 있음
env = gym.make('FrozenLake-v1', desc=None, map_name=map_size, is_slippery=is_slippery, render_mode='human')
total_test_episode = 10
rewards = []
for episode inrange(total_test_episode):
state, _ = env.reset()
episode_reward = 0whileTrue:
action = select_action(state)
new_state, reward, done, _, _ = env.step(action)
episode_reward += reward
if done:
rewards.append(episode_reward)
break
state = new_state
print("")
print("avg: " + str(sum(rewards) / total_test_episode))
if __name__ == "__main__" :
learn()
testing_after_learning()
테스트를 진행하면서is_slippery 옵션을 껐을 경우에는1.0 보상을 받으면 성공이고,is_slippery 옵션을 켰을 경우에는70% 이상 1.0 보상을 받으면 성공이라고 보실 수 있습니다.
추가로 is_slippery 옵션을 켰을 경우에는 학습을 많이 진행해야 어느 정도 수렴하시는 걸 보실 수 있습니다!
아무래도 model-free로 진행을 하니까 많이 느리더라구요ㅠㅠ
model-based
model-free가 아닌 어느 정도 model-based로 빠르게 학습을 하고 싶으신 경우 아래 상황을 고려할 수 있습니다.
행동 한 번을 진행할 때마다reward에 - 진행 → RL이 최단 경로로 진행하려는 경향을 학습할 수 있음
구멍에 빠졌을 경우,reward에 크게 - 진행 → 구멍에 빠지지 않는 쪽으로 빠르게 학습할 수 있음
도착했을 경우,reward를 크게 추가 → 도착 지점에 확실히 도착하기 위해 큰 reward를 지급
그 외에도 벽에 부딪히거나 하는 등 맵을 알고 있기 때문에 환경에 맞게reward를 추가로 주거나 마이너스를 진행하여,model-based 모델을 만들 수도 있습니다.
그래도 강화 학습을 제대로 알기 위해서는 model-free로 진행해보는 것을 추천드립니다!
Q-learning으로 frozen lake를 풀 때, 크게 두 가지를 생각하시면 됩니다.
Q 값을 바탕으로 행동을 선택
선택한 행동을 Q-learning 공식을 사용해서 Q 값 업데이트
위의 두 가지를 하나씩 자세히 살펴보겠습니다.
Q 값을 바탕으로 행동을 선택
해당 부분은 현재까지 업데이트 된 Q 값을 바탕으로 행동을 선택하는 것입니다.
기본적으로는 Q 값이 가장 높은 행동을 선택하면 됩니다.
하지만 여기에는 한 가지 문제점이 있습니다.
Q 값이 제대로 업데이트가 될 때까지 충분한 탐험을 진행하지 못했을 경우, 제대로 된 행동을 추출할 수 없다는 것입니다.
예를 들어, 초반에는 Q 값이 모두 0이기 때문에 (0, 0)에서 왼쪽으로 가는 행동만 선택하기 때문에 게임을 진행할 수가 없습니다.
저희는 이 문제를 해결하기 위해, ϵ-greedy 방법을 사용할 수 있습니다.
ϵ-greedy란?
탐험과 이용의 균형을 맞추기 위한 행동 선택 방법으로, 아래 공식을 따릅니다.
여기서 ϵ은 0과 1 사이의 값으로 ϵ 확률 만큼은 랜덤하게 행동을 하게 하여 탐험을 진행하도록 하고, (1-ϵ) 확률 만큼 Q 값이 가장 높은 행동을 선택하도록 합니다.
해당 ϵ을 초반에 높게 설정하고 점차 ϵ을 줄임으로써, 초반에는 랜덤 행동을 통한 탐험을 하게 하고 점차 Q 값을 이용하도록 행동을 선택할 수 있습니다.
ϵ-greedy를 활용하여 행동을 선택하는 코드는 아래와 같습니다.
# 초기 값은 보통 1로 설정
epsilon = 1.0
train = True# ϵ-greedy를 활용한 행동 선택defselect_action(state) :# 훈련을 할 경우에는 ϵ-greedy 방법을 사용# 테스트를 진행할 때는 온전히 Q 값만 사용# np.random.rand()를 넣어, 후반에도 종종 탐험을 할 수 있도록 함if np.random.rand() < epsilon and train :
action = np.random.choice([0, 1, 2, 3])
else :
action = np.argmax(Q[state])
return action
선택한 행동을 Q-learning 공식을 사용해서 Q 값 업데이트
해당 부분은 위에서 선택한 행동을 환경에서 실행해보고, 그 결과 값을 Q-learning 공식에 맞게 Q 값을 업데이트 하는 것입니다.
코드로 들어가기 전에 먼저 Q 테이블을 업데이트하는 공식을 먼저 살펴보겠습니다.
해당 수식은 Q(s, a)를 업데이트 하는데, 특정 학습률 α에 있어 (1- α)만큼 현재의 Q 값과 α만큼의 (보상값 r + 할인율 γ * 다음 state의 가장 높은 Q값 maxQ(s', a'))를 반영한다는 의미입니다.
학습률 α
값이 높을수록 다음 행동 값 즉, 새로운 정보를 더 많이 반영한다는 것이고, 낮을수록 현재의 Q 값 즉, 기존의 경험을 더 많이 유지한다는 의미입니다.
할인율 γ
미래 보상의 중요도를 나타내는 지표로, 보통은 미래의 보상에 너무 의존하지 않도록 1보다 약간 작은 수로 지정하는 것이 보통입니다.
maxQ(s', a')
다음 상태인 s'에서 가능한 모든 행동 중 가장 높은 Q 값을 의미하며, s'은 현재 state에서 위에서 고른 행동을 실행한 결과 값이라고 보시면 됩니다.
이제 해당 공식을 바탕으로 Q-learning을 하는 코드는 아래와 같습니다.
# 학습을 진행할 때는 render 모드 비활성화
env = gym.make('FrozenLake-v1', desc=None, map_name=map_size, is_slippery=is_slippery)
env.reset()
# 환경의 행동 범위 : 여기서는 상, 하, 좌, 우 총 4개
action_size = env.action_space.n
# defaultdict은 키가 없을 때 자동으로 기본값을 생성하기 때문에 강화 학습에서 많이 사용
Q = defaultdict(lambda: np.zeros(action_size))
alpha = 0.1
gamma = 0.99# 총 학습을 진행할 에피소드 수
max_episode = 10000deflearn() :
reward_list = []
for i inrange(1, max_episode+1) :
# 100번째 마다 학습이 진행되고 있음을 출력if i % 100 == 0 :
# 해당 에피소드까지 진행된 모든 보상의 평균을 구함
avg_reward = sum(reward_list)/100print("\rEpisode {}/{} || average reward {}".format(i, max_episode, avg_reward), end="")
reward_list = []
# 에피소드를 처음 시작할 때 reset
state, _ = env.reset()
done = False
all_reward = 0# 에피소드가 종료될 때까지 반복whilenot done :
# Q 테이블을 바탕으로 action을 고르는 함수
action = select_action(state)
# state, reward, done 외 사용하지 않기 때문에 _ 처리
new_state, reward, done, _, _ = env.step(action)
# Q-learning 공식
Q[state][action] = (1-alpha)*Q[state][action] + alpha*(reward + gamma*np.max(Q[new_state]))
all_reward += reward
state = new_state
# 50번째 에피소드 마다 ϵ 값을 줄여줌if i % 50 == 0 :
epsilon *= 0.99
reward_list.append(all_reward)
위의 두 가지 과정을 합치면 Q-learing으로 frozen lake를 풀 수 있는 코드가 완성됩니다!
학습 후 테스트를 진행하고 싶으신 경우에는 render를 킨 환경을 다시 세팅해서 해주시면 됩니다.
전체 코드
행동 선택, 학습, 테스트 과정을 모두 포함한 전체 코드는 아래와 같습니다.
import gymnasium as gym
from collections import defaultdict
import numpy as np
# 미끄러짐 옵션 True/False 선택 가능
is_slippery = True# 8x8 중에 선택 가능
map_size = '4x4'
env = gym.make('FrozenLake-v1', desc=None, map_name=map_size, is_slippery=is_slippery)
env.reset()
action_size = env.action_space.n
Q = defaultdict(lambda: np.zeros(action_size))
alpha = 0.1
gamma = 0.99
epsilon = 1.0
train = True
max_episode = 100000defselect_action(state) :if np.random.rand() < epsilon and train :
action = np.random.choice([0, 1, 2, 3])
else :
action = np.argmax(Q[state])
return action
deflearn() :global epsilon
reward_list = []
for i inrange(1, max_episode+1) :
# 100번째 마다 학습이 진행되고 있음을 출력if i % 100 == 0 :
# 해당 에피소드까지 진행된 모든 보상의 평균을 구함
avg_reward = sum(reward_list)/100print("\rEpisode {}/{} || average reward {}".format(i, max_episode, avg_reward), end="")
reward_list = []
state, _ = env.reset()
done = False
all_reward = 0whilenot done :
action = select_action(state)
new_state, reward, done, _, _ = env.step(action)
Q[state][action] = (1-alpha)*Q[state][action] + alpha*(reward + gamma*np.max(Q[new_state]))
all_reward += reward
state = new_state
if i % 50 == 0 :
epsilon *= 0.99
reward_list.append(all_reward)
# 학습한 Q를 바탕으로 frozen lake 테스트deftesting_after_learning():# render를 켜야 제대로 학습이 되었는지 확인할 수 있음
env = gym.make('FrozenLake-v1', desc=None, map_name=map_size, is_slippery=is_slippery, render_mode='human')
total_test_episode = 10
rewards = []
for episode inrange(total_test_episode):
state, _ = env.reset()
episode_reward = 0whileTrue:
action = select_action(state)
new_state, reward, done, _, _ = env.step(action)
episode_reward += reward
if done:
rewards.append(episode_reward)
break
state = new_state
print("")
print("avg: " + str(sum(rewards) / total_test_episode))
if __name__ == "__main__" :
learn()
testing_after_learning()
테스트를 진행하면서 is_slippery 옵션을 껐을 경우에는 1.0 보상을 받으면 성공이고, is_slippery 옵션을 켰을 경우에는 70% 이상 1.0 보상을 받으면 성공이라고 보실 수 있습니다.
추가로 is_slippery 옵션을 켰을 경우에는 학습을 많이 진행해야 어느 정도 수렴하시는 걸 보실 수 있습니다!
아무래도 model-free로 진행을 하니까 많이 느리더라구요ㅠㅠ
model-based
model-free가 아닌 어느 정도 model-based로 빠르게 학습을 하고 싶으신 경우 아래 상황을 고려할 수 있습니다.
행동 한 번을 진행할 때마다 reward에 - 진행 → RL이 최단 경로로 진행하려는 경향을 학습할 수 있음
구멍에 빠졌을 경우, reward에 크게 - 진행 → 구멍에 빠지지 않는 쪽으로 빠르게 학습할 수 있음
도착했을 경우, reward를 크게 추가 → 도착 지점에 확실히 도착하기 위해 큰 reward를 지급
그 외에도 벽에 부딪히거나 하는 등 맵을 알고 있기 때문에 환경에 맞게 reward를 추가로 주거나 마이너스를 진행하여, model-based 모델을 만들 수도 있습니다.
그래도 강화 학습을 제대로 알기 위해서는 model-free로 진행해보는 것을 추천드립니다!
Q-learning이랑 비슷한 SARSA로 frozen lake 문제를 푸는 방법은 아래 링크를 참고해주세요.
선물에 있는 곳에 도착하거나,구멍에 빠지면에피소드 종료 → 선물에 있는 곳에 도착해야만 보상1을 획득할 수 있음
움직임은상, 하, 좌, 우존재
얼음 내미끄러짐을 키고 끌 수 있음 → 미끄러짐을 킬 경우, 각얼음마다 특정 확률로 다른 곳으로 움직이는 확률이 존재 → 각 얼음마다 존재하는 미끄러질 확률을 조절할 수 없음
저희는 위의 규칙을 잘 생각하여,구멍에 빠지지 않고 선물에 도착하는 경로를 학습해주어야 합니다.
필요한 라이브러리 설치
frozen lake는 gymnasium에서 제공하고 있기 때문에 가장 먼저gymnasium을 설치해주시면 됩니다!
그리고render 모드 활성화를 진행하기 위해gymnasium[toy-text]설치도 같이 진행해주세요.
두 패키지 모두pip install로 설치해주시면 금방 설치할 수 있습니다.
import gymnasium as gym
from collections import defaultdict
import numpy as np
frozen lake 환경 세팅
필요한 라이브러리를 설치한 후에는 frozen lake 환경을 세팅해봅니다.
우선 환경 세팅을 하는 코드는 아래와 같습니다.
# 미끄러지는 얼음을 만들지 결정하는 변수
is_slippery = False# 맵 사이즈
map_size = '4x4'# frozen lake 환경 설정# render 활성화 환경
env = gym.make('FrozenLake-v1', desc=None, map_name=map_size, is_slippery=is_slippery, render_mode='human')
# 환경을 초기화하는 함수
env.reset()
env.reset()의 경우 기본 기능은 환경을 초기화하는 함수지만,환경을 세팅한 다음에 해당 코드를 부르지 않으면 오류가 발생하니 반드시 환경 사용 전에 env.reset()을 먼저 불러주세요!
frozen lake 테스트 진행하기
이제 만든 환경을 바탕으로 gymnasium에서 제공하는 frozen lake 테스트를 진행해봅시다!
테스트를 진행하는 코드는 아래와 같습니다.
whileTrue:
# 0 : 왼쪽, 1 : 아래, 2 : 오른쪽, 3 : 위
action = input("이동할 방향: ")
if action notin ['0','1','2','3']:
continue
action = int(action)
# step() : 환경에 액션을 넣고 실행하는 함수
state, reward, done, info, prob = env.step(action)
print("위치: ", state, "행동: ", action, "보상: ", reward)
print()
if done:
print("에피소드 종료", reward)
break
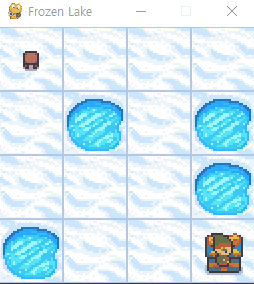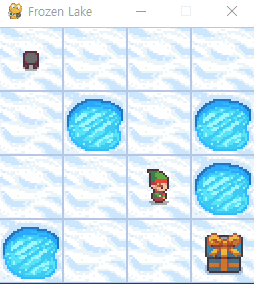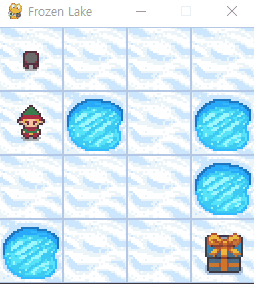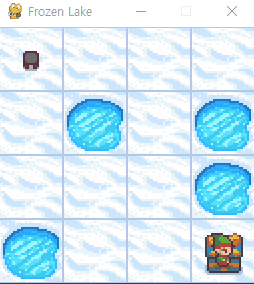
해당 코드를 실행해보면, 4x4 맵이 있는 창에 입력한 행동대로 움직이는 것을 확인할 수 있습니다.
구멍에 빠지거나 선물에 도착하기 전에는 계속 움직일 수 있으니, 환경을 이해하기 위해 편하게 테스트 진행해보세요!
맵을 키우거나미끄러지는 얼음을 키고 테스트해보시는 것도 추천드립니다.
여기까지가 frozen lake 환경 세팅이었습니다.
이번 포스팅에서는 Q-learning과 SARSA에 관한 model-free 전체 코드만 업로드 되어 있습니다.
두 가지 모두is_slippery가 False일 경우에는 1.0만점을 받았고,is_silppery가 True일 경우에는0.8 이상의 보상을 획득했습니다.