안녕하세요. 오늘은 크롤링 데이터로 워드클라우드(wordcloud)를 만드는 방법에 대해 포스팅 하겠습니다.
크롤링 데이터는 네이버 뉴스 크롤링을 사용할 예정입니다!
네이버 뉴스 크롤링 과정이 궁금하신 분은 아래 링크를 확인해주세요:)
[Crawling] 네이버 뉴스 크롤링 - 1
안녕하세요. 크롤링에서 가장 첫 포스팅을 네이버 뉴스 크롤링으로 하게 되었어요. 아무래도 바쁜 일상 속에서 매일 뉴스 기사를 파악하는 부분이 시간적으로 힘들었는데, 크롤링하고 데이터
yhj9855.com
- 워드클라우드(wordcloud)란?
자료의 빈도를 시각적으로 나타내는 방법 중 하나로, 텍스트 데이터 분석을 진행할 때 많이 사용됩니다.

위의 그림처럼 글자 크기를 빈도수에 비례하여 나타내주기 때문에 어떤 단어가 중요한지 한 눈에 알기 편합니다.
만들기 어려워 보이지만, 파이썬은 워드 클라우드를 만드는 라이브러리를 제공해주기 때문에 굉장히 쉽게 만들 수 있습니다!
워드 클라우드를 만드는 건 Jupyter Notebook에서 하시는 걸 추천드립니다.
Jupyter Notebook을 설치하고 사용하는 방법은 아래 링크에서 확인해주세요!
주피터 노트북(Jupyter Notebook) 사용하기
안녕하세요! 오늘은 데이터 분석에서 자주 활용하는 주피터 노트북(Jupyter Notebook) 을 사용하는 방법에 대해서 포스팅 하겠습니다. 주피터 노트북이란? 대화형 컴퓨팅 환경을 제공하는 오픈 소스
yhj9855.com
그럼 한글 텍스트 데이터로 워드 클라우드를 만들어보도록 하겠습니다.
- 필요한 라이브러리 설치
워드 클라우드는 텍스트 데이터를 다루기 때문에 텍스트 데이터를 다루는 라이브러리가 필요합니다.
파이썬은 텍스트 데이터가 영어냐, 한글이냐에 따라서 필요한 라이브러리가 다른데요.
저희는 한글 텍스트 분석을 진행할 것이기 때문에 Konply 라이브러리를 설치합니다.
Konply 라이브러리와 관련된 자세한 설명은 아래 포스팅에서 확인해주세요!
https://yhj9855.com/entry/%ED%95%9C%EA%B5%AD%EC%96%B4-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D-%ED%95%84%EC%88%98-%EB%9D%BC%EC%9D%B4%EB%B8%8C%EB%9F%AC%EB%A6%AC-Konlpy%EC%BD%94%EC%97%94%EC%97%98%ED%8C%8C%EC%9D%B4
한국어 데이터 분석 필수 라이브러리 Konlpy(코엔엘파이)
안녕하세요! 오늘은 한국어 데이터 분석을 위해 꼭 필요한 Konlpy(코엔엘파이) 라이브러리에 대해서 포스팅 하겠습니다. Konlpy 란? 한국어 자연어 처리를 위한 파이썬 라이브러리 입니다. Konlpy의
yhj9855.com
그 다음 워드 클라우드를 만들기 위한 라이브러리 wordcloud를 설치해줍니다.
# cmd 창에서 wordcloud 라이브러리 설치
pip install wordcloud- 데이터 로드 후 정제하기
필요한 라이브러리를 설치한 후에는 pandas를 사용하여 데이터를 불러옵니다.
저는 2024년 01월 17일 네이버 게임/리뷰 카테고리의 기사 크롤링 데이터를 불러와 정제를 진행하도록 하겠습니다.
result = pd.read_excel('news_detail_20240117.xlsx')
# 기사의 제목 데이터
Title = list(result['title'])
# 기사의 내용 데이터
Information = list(result['information'])
Total = []
# 기사의 제목과 내용을 하나의 리스트에 담았다.
for i in range(len(result)) :
Total.append(Title[i]+' '+Information[i])※ Total 데이터의 양이 너무 많아서 데이터 확인은 진행하지 않겠습니다.
- 명사로 데이터 분류하기
워드 클라우드를 만들기 위해서는 데이터를 의미 있는 데이터만 남겨야 합니다.
그 중 가장 빠른 방법이 명사인 데이터만 남기는 것인데요.
생각보다 동사는 '이다', '한다', '있다', '었다' 와 같이 보기만 하면 이해하지 못하는 단어의 빈도수가 높은 경우가 많습니다.
그 외에 다른 형태소를 사용하거나, 범위를 넓힐 경우 워드 클라우드로 만들었을 때, 깔끔하게 나오지 않는 경우가 많아 명사로 진행하도록 하겠습니다.
Konply가 지원하는 형태소 분석 종류가 몇 가지 있는데, 저는 그 중에서 Komoran을 사용하였습니다.
다른 종류나 종류별 차이에 대한 포스팅은 추후에 진행하도록 하겠습니다!
명사로 형태소 분석을 하는 코드는 아래와 같습니다.
# 형태소 분석기로 Komoran을 사용
komoran = Komoran()
# Total 데이터를 명사로 분류한 후에 띄어쓰기로 붙여넣기 진행
# 줄바꿈으로 진행해도 상관없으나, 보기에 띄어쓰기가 더 편하기 때문에 띄어쓰기로 진행
total_nouns = [' '.join(komoran.nouns(doc)) for doc in Total]
- 추가 전처리 진행하기
total_nouns 데이터는 이제 명사로만 이루어진 데이터입니다.
그대로 워드 클라우드로 진행을 해도 되지만, 생각보다 의미 없는 데이터가 워드 클라우드에 들어가는 경우가 많기 때문에 추가적으로 데이터 전처리를 진행하는 것이 좋습니다.
예를 들면 한 글자 '것', '이', '등' 이런 단어의 빈도수가 높은 경우가 많기 때문에 두 글자 명사만 데이터를 넣어준다거나, 특정 카테고리의 뉴스이기 때문에 자주 등장하는 명사는 제거한다거나 하는 방법으로 데이터 전처리를 진행해주시면 됩니다.
제가 진행한 전처리 코드는 아래와 같습니다.
# 추가 데이터 전처리 과정
for i in range(len(total_nouns)) :
# 게임 뉴스이기 때문에 게임과 관련된 부분, 뉴스와 관련된 부분은 제거한다.
# total_nouns[i]가 하나의 문자열이기 때문이 replace를 통해 제거한다.
total_nouns[i] = total_nouns[i].replace('게임', '')
total_nouns[i] = total_nouns[i].replace('기자', '')
total_nouns[i] = total_nouns[i].replace('기사', '')
total_nouns[i] = total_nouns[i].replace('진행', '')
total_nouns[i] = total_nouns[i].replace('이용자', '')
total_nouns[i] = total_nouns[i].replace('플레이', '')
total_nouns[i] = total_nouns[i].replace('이번', '')
# 단어를 구분해야 하기 때문에 띄어쓰기로 나누어준다.
# 만약 줄바꿈으로 데이터를 붙여 넣었다면, 줄바꿈으로 나누어주어야 한다.
a = total_nouns[i].split(' ')
# 단어가 두 글자 이상인 것만 워드 클라우드를 진행할 데이터에 넣어준다.
data = ''
for j in a :
if len(j) >= 2 :
# 이전 코드와 동일한 이유로 띄어쓰기로 붙여 넣는다.
# 마찬가지로 줄바꿈으로 진행해도 상관없다.
data = data+' '+j
total_nouns[i] = data- 워드 클라우드 만들기
이제 데이터 전처리가 완료되었으니, 워드 클라우드를 만들어보겠습니다!
워드 클라우드를 만드는 코드는 아래와 같습니다.
# 워드 클라우드를 위한 작업
wordcloud = []
for i in total_nouns :
# 문자열로 된 데이터를 단어로 판단해야 하기 때문에 띄어쓰기로 나눈다.
# 줄바꿈으로 붙여 넣기를 진행했다면, 줄바꿈으로 나누어야 한다.
i = i.split(' ')
# wordcloud라는 리스트에 모든 단어를 넣어준다.
for j in i :
wordcloud.append(j)
# Counter 함수를 사용하여 wordcloud 내 단어와 단어의 수를 wordcloud_data에 dictionary 형태로 저장한다.
wordcloud_data = dict(Counter(wordcloud))
# 워드 클라우드의 모양 이미지 변경하고 싶을 경우 파일 경로를 저장한다.
# 기본 네모로 진행할 경우 해당 부분은 지우면 된다.
Naver = np.array(Image.open("파일 경로"))
# 워드 클라우드의 크기를 결정한다.
plt.figure(figsize=(30,30))
wc = WordCloud( # 워드 클라우드의 모양을 결정한다.
# 기본 네모로 진행할 경우 해당 부분을 지우면 된다.
relative_scaling=0.2,mask = Naver,
# 기본적으로 한글은 지원하지 않기 때문에 한글의 폰트를 지정해야한다.
# 워드 클라우드는 함수 안에서 폰트를 지정하기 때문에 다른 그래프보다 폰트 자유도가 높다.
font_path="폰트 경로",
# 워드 클라우드 배경색
background_color="white",
# 가장 작은 폰트 사이즈
min_font_size=1,
# 가장 큰 폰트 사이즈
max_font_size=50,
# 워드 클라우드 진행하고 싶은 단어의 수
max_words=100,
colormap = 'coolwarm'
).generate_from_frequencies(wordcloud_data)
plt.imshow(wc)
plt.axis('off')
plt.show()위의 있는 코드로 실행했을 때의 결과물은 아래와 같습니다!
※ 실행할 때마다 색상이 일부 달라지기 때문에 원하는 색상이 나올 때까지 진행하시면 됩니다.


저는 오른쪽 이미지를 사용했기 때문에 해당 모양의 워드 클라우드가 만들어졌습니다.
생각보다 이미지 적용이 잘되기 때문에 원하시는 이미지로 해보시길 바랍니다.
전체코드
import pandas as pd
import numpy as np
from konlpy.tag import *
from collections import Counter
from wordcloud import WordCloud
from wordcloud import ImageColorGenerator
from PIL import Image
import matplotlib.pyplot as plt
result = pd.read_excel('파일 이름')
Title = list(result['title'])
Information = list(result['information'])
Total = []
for i in range(len(result)) :
Total.append(Title[i]+' '+Information[i])
komoran = Komoran()
total_nouns = [' '.join(komoran.nouns(doc)) for doc in Total]
for i in range(len(total_nouns)) :
total_nouns[i] = total_nouns[i].replace('게임', '')
total_nouns[i] = total_nouns[i].replace('기자', '')
total_nouns[i] = total_nouns[i].replace('기사', '')
total_nouns[i] = total_nouns[i].replace('진행', '')
total_nouns[i] = total_nouns[i].replace('이용자', '')
total_nouns[i] = total_nouns[i].replace('플레이', '')
total_nouns[i] = total_nouns[i].replace('이번', '')
a = total_nouns[i].split(' ')
data = ''
for j in a :
if len(j) >= 2 :
data = data+' '+j
total_nouns[i] = data
wordcloud = []
for i in total_nouns :
i = i.split(' ')
for j in i :
wordcloud.append(j)
wordcloud_data = dict(Counter(wordcloud))
Naver = np.array(Image.open("파일 경로"))
plt.figure(figsize=(30,30))
wc = WordCloud( relative_scaling=0.2,mask = Naver,
font_path="폰트 경로",
background_color="white",
min_font_size=1,
max_font_size=50,
max_words=100,
colormap = 'coolwarm'
).generate_from_frequencies(wordcloud_data)
plt.imshow(wc)
plt.axis('off')
plt.show()
- 활용하기
제가 개인적으로 워드클라우드와 다른 시각화를 활용하여 네이버 기사를 분석한 예시입니다.

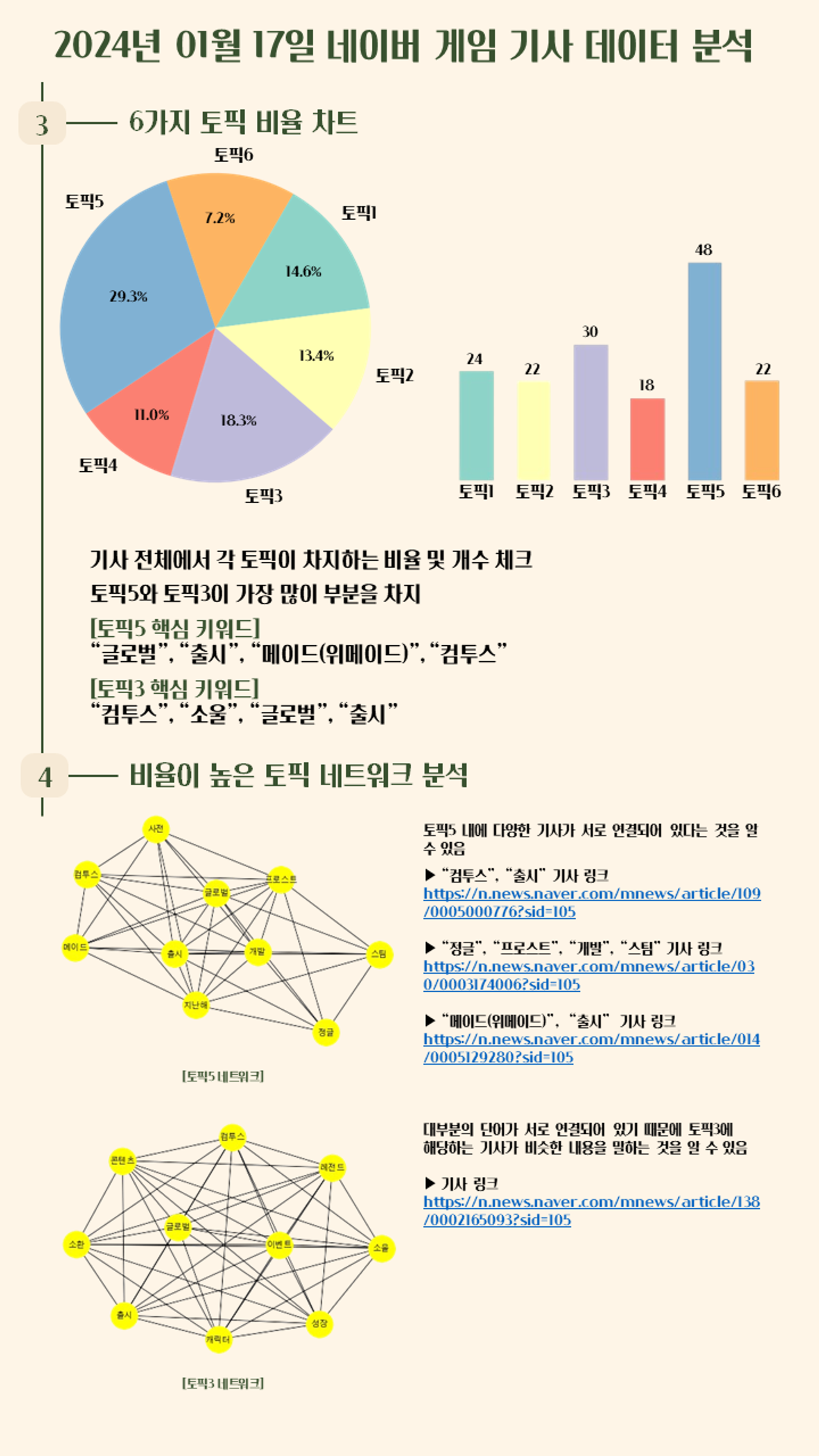
예시에서 사용한 파이 차트 및 바 차트, 네트워크 분석은 다음 포스팅에서 진행하겠습니다!!
한글 데이터로 토픽모델링을 하는 방법이 궁금하신 분들은 아래 링크를 확인해주세요:)
[데이터 분석] 한글 데이터 토픽 모델링 진행하기
안녕하세요! 오늘은 한글 데이터로 토픽 모델링(topic modeling)을 하는 방법에 대해 포스팅 하겠습니다. 한글 데이터는 네이버 뉴스 크롤링 데이터를 사용할 예정입니다. 네이버 뉴스 크롤링 과정
yhj9855.com
코드에 대해 궁금한 부분이 있으신 분들은 댓글로 남겨주시면, 답변 드리도록 하겠습니다.

★ 읽어주셔서 감사합니다★
'Python(파이썬) > Data Analysis(데이터 분석)' 카테고리의 다른 글
| [데이터 분석] 한글 데이터 토픽 모델링 진행하기 (84) | 2024.02.02 |
|---|