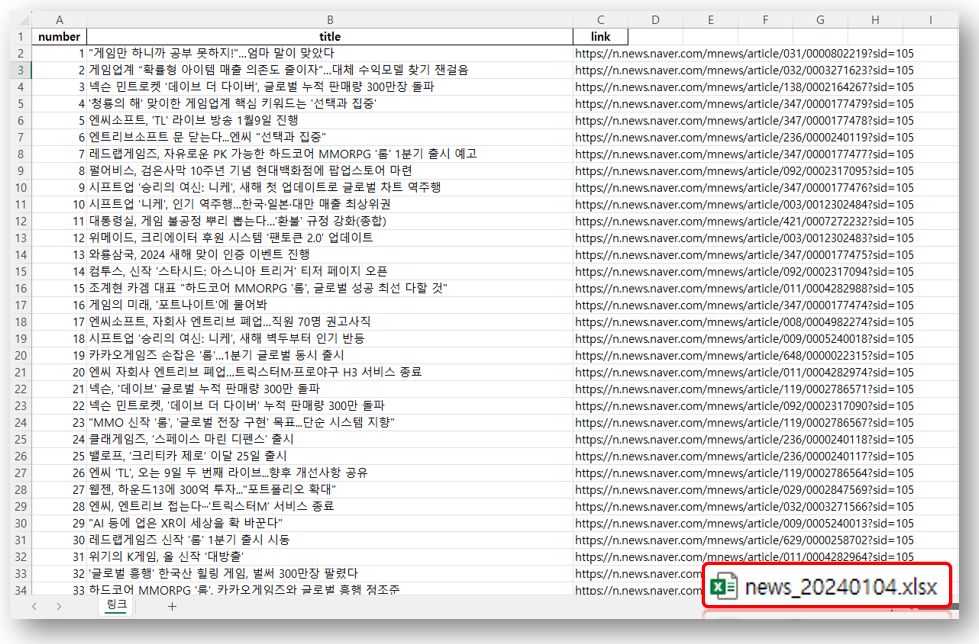
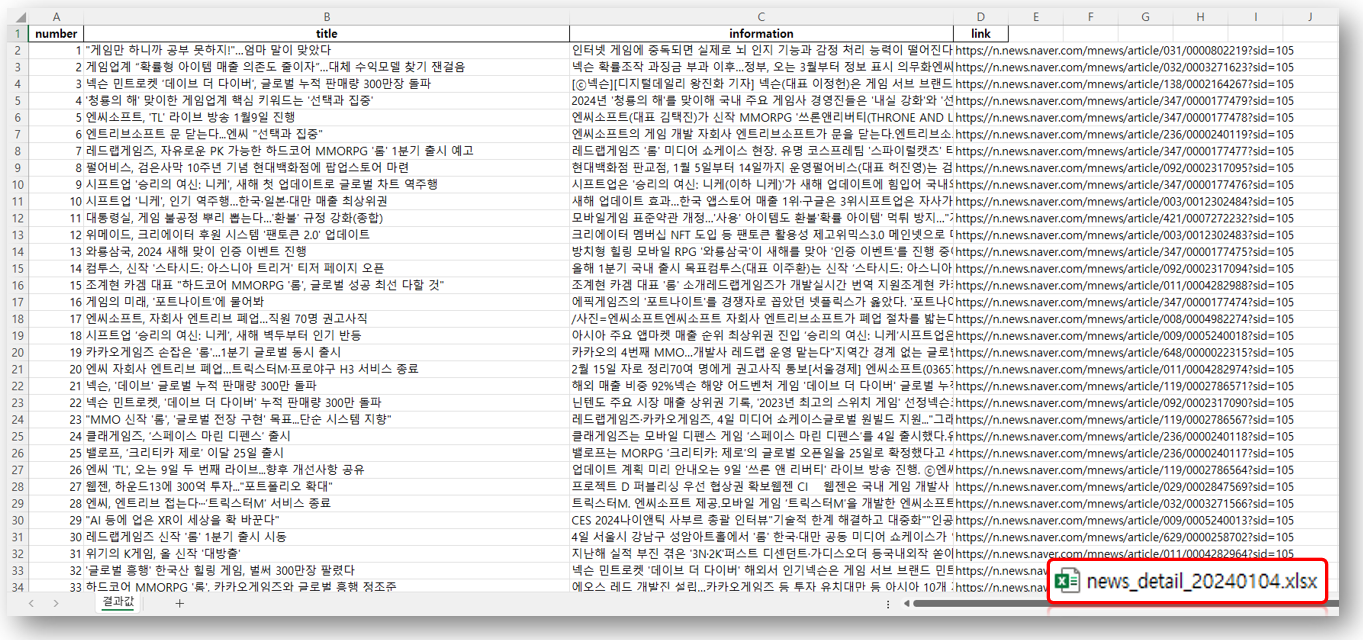
안녕하세요. 오늘은 기존에 작성한 네이버 뉴스 크롤링 코드에서 첫 번째 코드의 자세한 크롤링 과정을 포스팅 하겠습니다.
네이버 뉴스 크롤링 전체 코드를 확인하고 싶으신 분들은 아래 링크를 확인해주세요!
https://yhj9855.com/entry/Crawling-%EB%84%A4%EC%9D%B4%EB%B2%84-%EB%89%B4%EC%8A%A4-%ED%81%AC%EB%A1%A4%EB%A7%81-1
[Crawling] 네이버 뉴스 크롤링 - 1
안녕하세요. 크롤링에서 가장 첫 포스팅을 네이버 뉴스 크롤링으로 하게 되었어요. 아무래도 바쁜 일상 속에서 매일 뉴스 기사를 파악하는 부분이 시간적으로 힘들었는데, 크롤링하고 데이터
yhj9855.com
첫 번째 코드는 Python으로 특정 날짜의 네이버 게임/리뷰 카테고리의 기사들을 크롤링하는데, 제목과 링크만 가지고 오는 코드였습니다.
- 기본 링크 설정하기
크롤링을 시작할 때 크롤링하고자 하는 페이지의 링크를 설정하는 것이 가장 중요합니다.
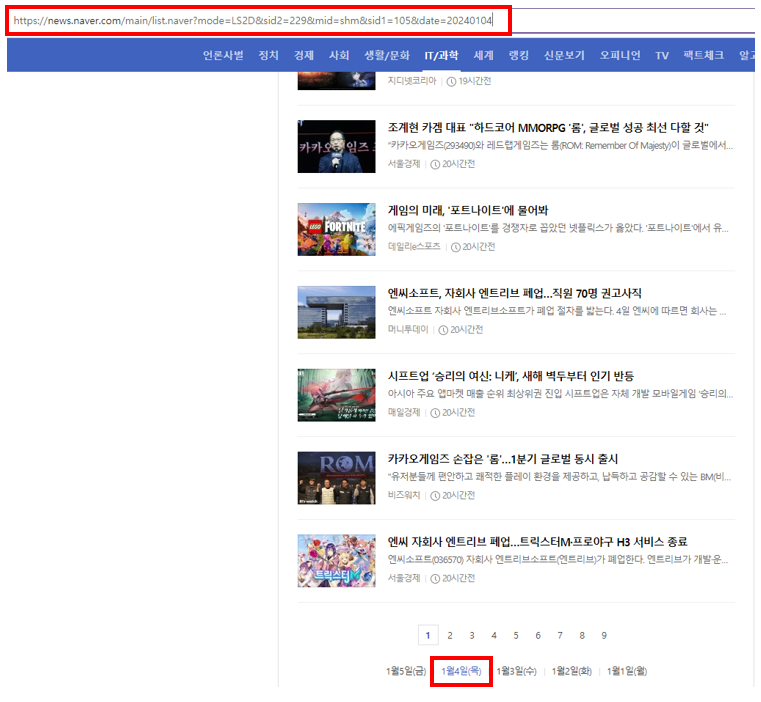
위의 그림처럼 2024년 1월 4일의 게임/리뷰 카테고리의 뉴스를 크롤링하고자 한다면 원하는 정보가 담긴 링크는
아래 링크와 같습니다.
https://news.naver.com/main/list.naver?mode=LS2D&mid=shm&sid2=229&sid1=105&date=20240104
해당 링크에서 가장 중요한 것은 바로 date=20240104 부분인데요
네이버 뉴스의 경우 날짜를 링크 자체에서 구분할 수 있게 되어 있습니다.
그렇기 때문에 특정 날짜의 기사들을 크롤링하고 싶다면 date 뒤에 연도+월+일 붙이면 된다는 사실을 알 수 있습니다.
해당 부분을 코드로 변경하면 아래와 같습니다.
# 수집하고자 하는 메인 링크
link = 'https://news.naver.com/main/list.naver?mode=LS2D&sid2=229&sid1=105&mid=shm&date='
# 크롤링하고 싶은 날짜를 년도월일 나열해준다.
# 날짜를 쉽게 바꾸기 위해 date를 따로 선언해준다.
date = '20240104'
# 메인 링크는 링크에 날짜가 붙은 구조이기 때문에 이렇게 작성해준다.
main_link = link + date<크롤링 하고자 하는 URL 찾기 Tip>
링크를 확인할 때 오늘 날짜, 첫 페이지와 같이 기본적으로 접속하면 바로 볼 수 있는 URL로 확인하는 건 피하시는게 좋습니다.
기본으로 설정된 URL은 해당 URL만 특별하게 설정되어 있거나, 보이는 링크와 실제 링크가 다른 경우도 종종 있기 때문에 오류가 발생하기 쉽습니다.
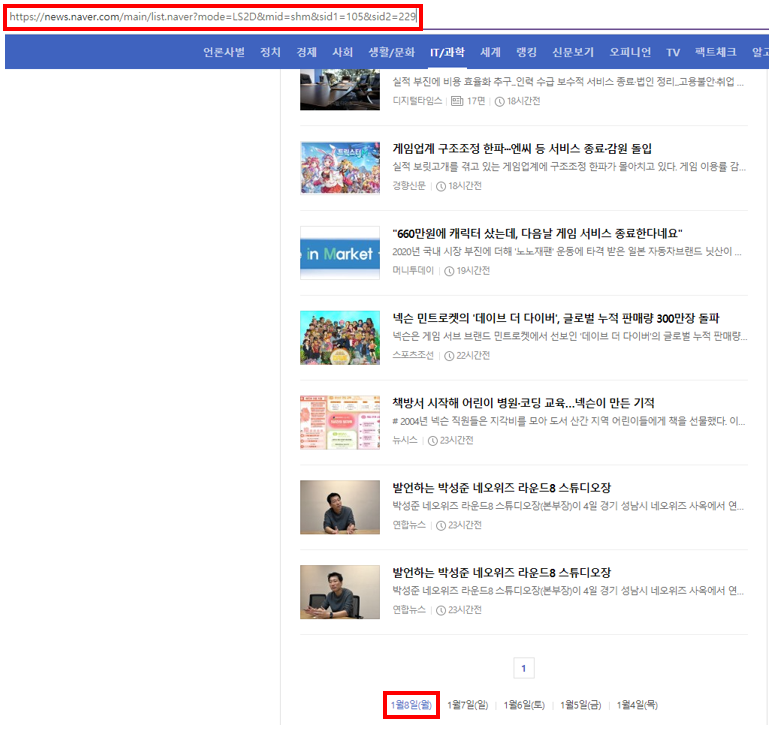
아래 그림처럼 '오늘' 날짜의 뉴스 기사에는 date 표시가 되어있지 않기 때문에 초기 링크를 설정할 때 어려움이 있을 수 있습니다.
- 페이지 링크 확인하기
원하는 날짜의 모든 기사를 크롤링하기 위해서는 모든 페이지의 기사를 크롤링할 수 있어야 합니다.
그러기 위해서 페이지가 변경될 때 어떤 링크의 변화가 있는지 확인해보도록 하겠습니다.
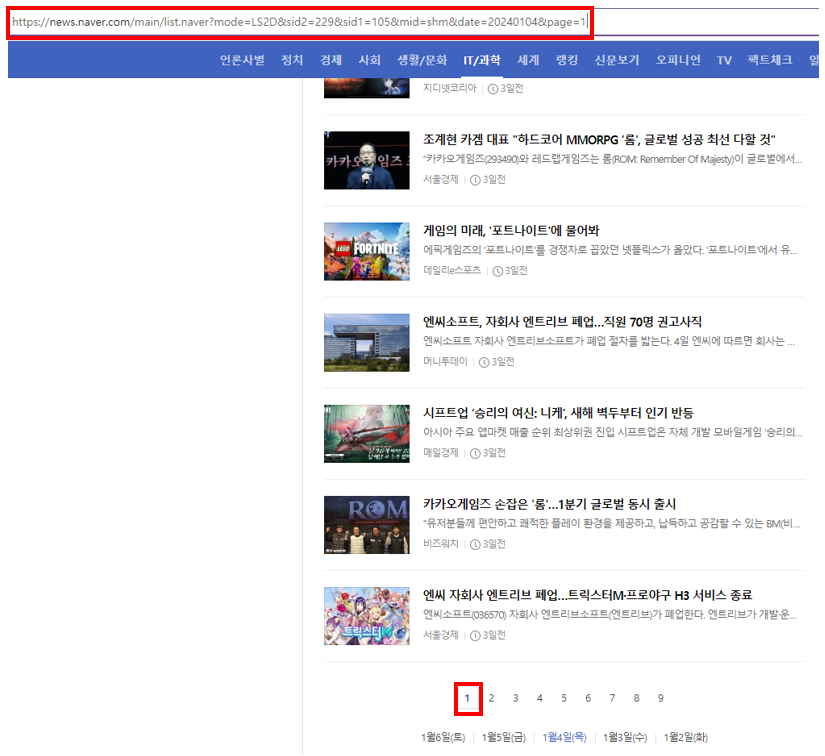
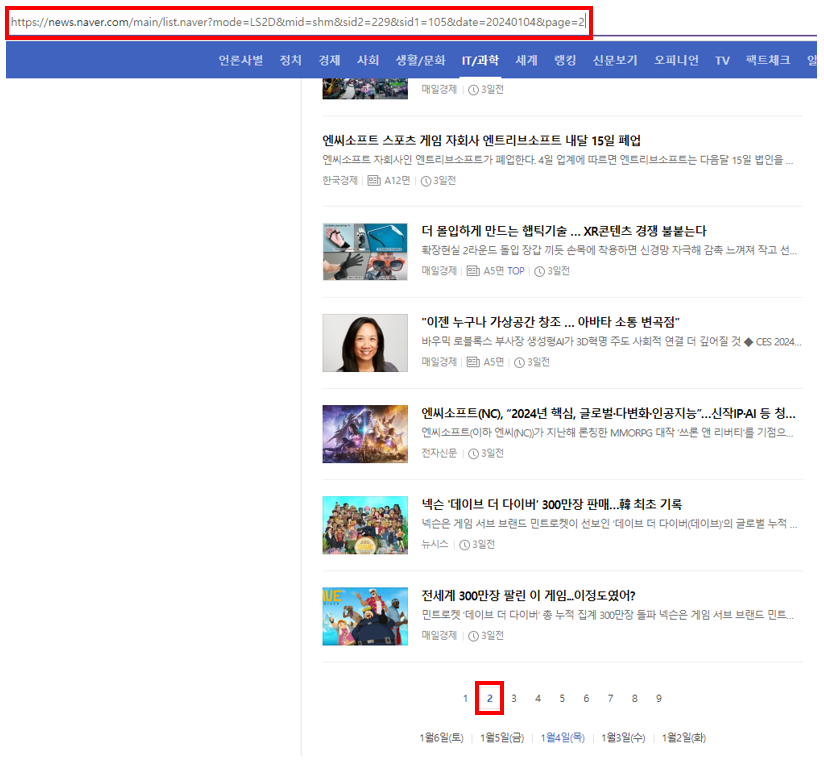
위의 그림처럼 동일 날짜 내 페이지가 2페이지로 변경되면 바뀌는 URL은 아래와 같습니다.
※ 1페이지의 링크는 초기 1페이지에서는 확인할 수 없지만 다른 페이지 → 1페이지 실행 시, 다른 페이지와 동일한 방식의 링크를 보여주는 것을 확인할 수 있습니다.
https://news.naver.com/main/list.naver?mode=LS2D&sid2=229&sid1=105&mid=shm&date=20240104&page=2
해당 링크에서 중요한 부분은 '&page=2' 부분입니다.
네이버 뉴스의 경우 페이지를 링크 자체에서 구분할 수 있게 되어 있습니다!
그렇기 때문에 페이지를 변경하고 싶을 경우, &page=페이지 번호 을 붙이면 된다는 사실을 알 수 있습니다.
저희가 크롤링하고자 하는 기사들은 모두 날짜, 페이지에 따라서 달라지는데, 둘 다 모두 링크 자체에서 변화를 줄 수 있습니다.
즉, 링크가 변하지 않고 데이터가 바뀌는 동적 페이지가 존재하지 않기 때문에 2가지 크롤링 방법이 존재합니다.
- Beautifulsoup을 활용한 정적 크롤링
- Selenium을 활용한 동적 크롤링
저는 여기서 정적 크롤링을 사용하였습니다!
정적 크롤링을 사용한 이유는 정적 크롤링은 chrome의 버전과 상관없이 언제든 사용할 수 있고, 동적 크롤링보다 속도가 월등히 빠르기 때문입니다.
저는 개인적으로 정적 크롤링과, 동적 크롤링 모두 사용할 수 있다면 정적 크롤링을 사용하시는 것을 추천드립니다!!
- 페이지 수를 확인하기
이제 페이지 링크를 확인했으니, 페이지 별로 기사를 크롤링 하는 방법만 남았습니다.
하지만 페이지의 수는 날짜마다 다르기 때문에 페이지의 끝을 알아야 합니다.
페이지의 끝을 찾아야 하는 이유는 아래 그림과 같습니다.
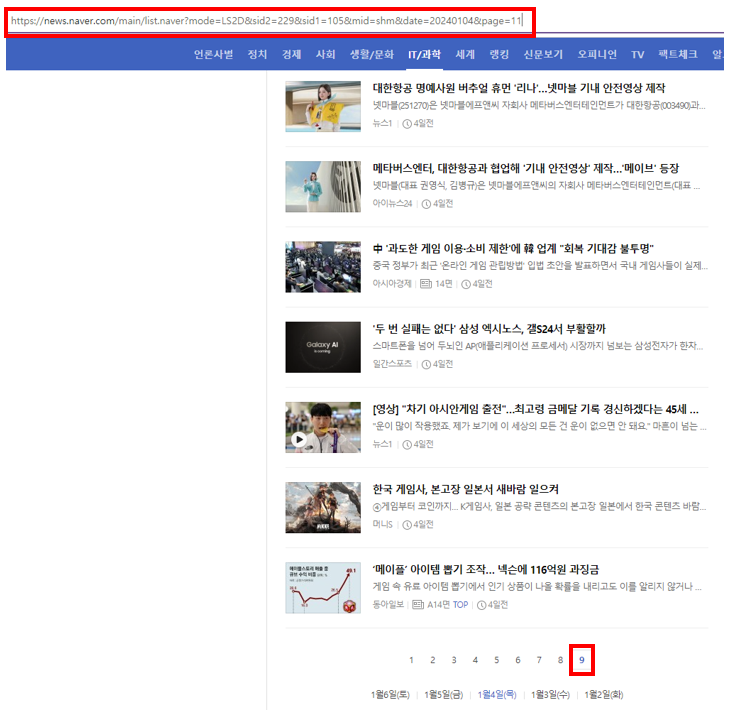
2024년 1월 4일에는 9페이지까지 존재하는데, 링크에 11페이지를 넣어도 오류가 발생하지 않는 것을 볼 수 있습니다.
즉, 네이버 뉴스는 해당하는 링크의 페이지가 존재하지 않거나, 오류가 발생하는 종류의 코드를 사용할 수 없기 때문에 반드시 페이지의 끝을 찾아야 올바르게 페이지를 탐색할 수 있습니다.
페이지의 끝을 찾기 위해서는 먼저 페이지 마지막 버튼이 어떤 HTML 구조를 가지고 있는지 확인을 해야 합니다.
모든 페이지의 HTML 구조를 확인하기 위해서는 '개발자 도구' 창을 열어야 합니다.
개발자 도구에 대한 자세한 설명은 아래 링크를 확인해주세요!
크롬 개발자 도구 사용하기
안녕하세요. 오늘은 크롤링을 진행하기 위해 반드시 필요한 개발자 도구를 사용하는 법에 대해서 포스팅 하겠습니다. 크롬 개발자 도구란? 크롬 브라우저에 직접 내장된 웹 개발 도구로, 웹 페
yhj9855.com
그 중에서 저희는 페이지 끝에 있는 버튼의 구조를 알고 싶은 것이기 때문에 아래 그림처럼 따라합니다.
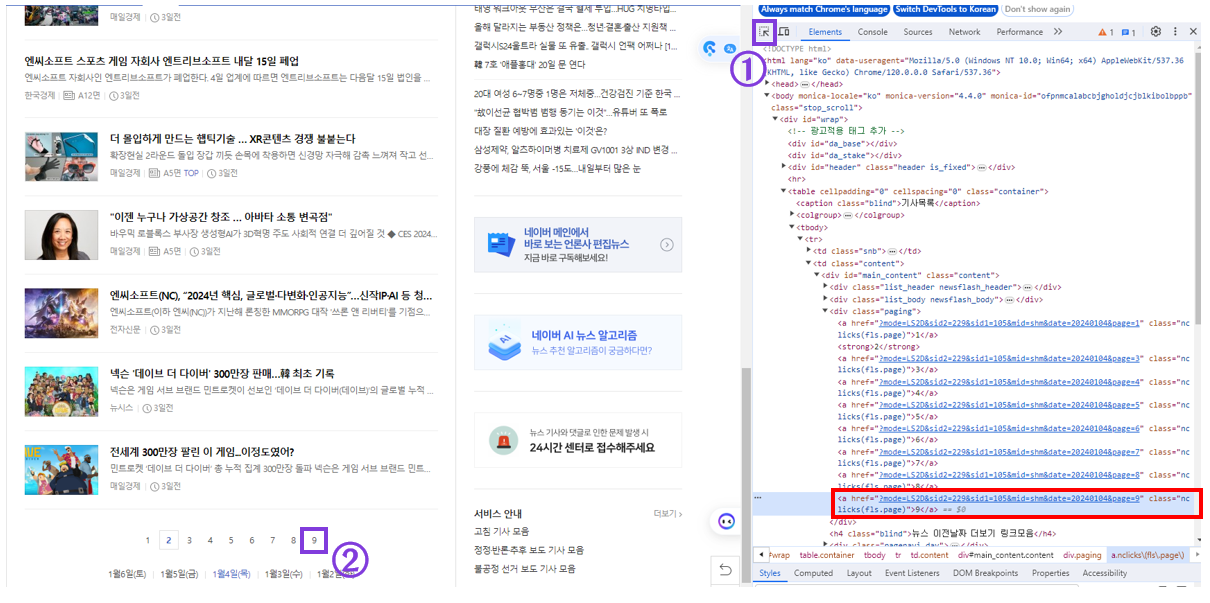
①번의 아이콘을 클릭한 후, ②번(=원하는 정보)을 클릭하면 원하는 정보의 HTML 구조로 바로 이동이 됩니다.
원하는 정보의 HTML 구조를 확인해보니, 아래와 같이 나왔습니다.
<a href="?mode=LS2D&sid2=229&sid1=105&mid=shm&date=20240104&page=9" class="nclicks(fls.page)">9</a>
HTML 구조의 뜻
- 'a' 태그: 링크가 담겨져 있는 공간이면 해당 태그를 사용합니다. 현재 페이지 버튼에는 해당 페이지의 링크 정보가 담겨져 있기 때문에 a 태그가 사용된 것입니다.
- href: 링크의 주소를 가지고 있는 부분입니다. 전체 링크를 가지고 있는 경우도 있지만, 대부분 주로 변경이 되는 부분만 따로 담고 있는 경우가 많습니다.
- class: 태그의 속성을 나타내는 부분입니다. 크롤링을 진행할 때 많이 사용되는 부분으로 ID가 없을 경우에는 이름처럼 사용되기도 합니다.
저희는 지금 페이지의 마지막을 알고 싶기 때문에 HTML 구조에서 '9'라는 부분을 가져오고 싶습니다.
9 부분은 class가 nclicks(fls.page)이고, a태그인 HTML 구조의 텍스트입니다.
하지만 그림을 보면, 현재 페이지인 2페이지를 제외하면 모두 동일한 구조를 가지고 있는 것을 볼 수 있습니다.
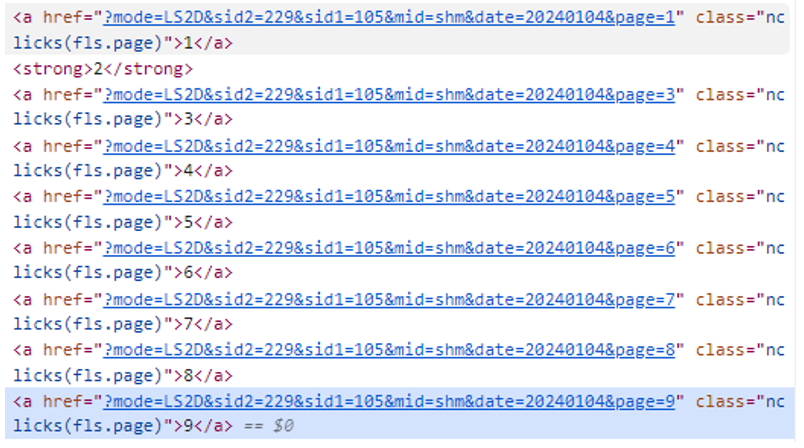
이런 경우에는 조건을 만족하는 모든 페이지를 가져온 다음, 가장 마지막만 가지고 오면 됩니다.
해당 부분을 코드로 변경하면 아래와 같습니다.
# Beautifulsoup으로 코드를 가져오기 위해서 꼭 필요한 과정
# 해당 홈페이지에 올바르게 접근할 경우에는 해당 부분에서 오류가 발생하지 않는다.
# 보통의 페이지에서는 headers가 필요 없는데, 네이버는 접근을 막는 경우가 있어서 headers를 추가해야 한다.
respose = requests.get(main_link, headers={'User-Agent':'Moailla/5.0'})
# main_link의 전체 HTML 구조를 가지고 온다.
html = respose.content
soup = BeautifulSoup(html, 'html.parser')
# 페이지에 해당 하는 부분이 a태그에 class가 nclilcks(fls.page)이기 때문에 이렇게 사용한다.
# find_all인 이유는 동일한 구조가 여러 개 있기 때문이다.
# find를 사용할 경우에는 동일한 구조가 여러 개 있을 경우 가장 앞에 있는 것만 가지고 오고,
# find_all을 사용할 경우에는 동일한 구조 여러 개를 모두 가져와서 리스트로 저장한다.
# 즉, Page는 리스트인 것이다.
Page = soup.find_all('a', {'class' : 'nclicks(fls.page)'})
try :
# 가장 마지막 페이지를 가지고 오기 위해서 리스트의 가장 마지막 부분을 받아온다.
end_page = Page[-1].text
# 페이지가 한 페이지 밖에 없을 경우에는 오류가 발생한다.
except :
end_page = 1
페이지별 링크와 마지막 페이지까지 찾았으니, 반복문을 통해서 페이지 별 링크에 접속하는 코드도 생성해봅니다.
# 기사의 수, 제목, 링크를 받아올 예정이기 때문에 정보를 담아줄 데이터 프레임을 생성한다.
Main_link = pd.DataFrame({'number' : [], 'title' : [], 'link' : []})
# 기사의 수를 담을 변수
number = 0
# end_page는 문자열이기 때문에 정수로 변환하여 사용한다.
for i in range(1, int(end_page)+1) :
page_link = main_link + '&page=' + str(i)- 기사의 제목과 링크 가져오기
마지막으로 크롤링 목적인 기사의 제목과 링크를 가져오기만 하면 첫 번째 코드의 크롤링이 완료됩니다!
페이지 수를 확인했던 것처럼 개발자 도구에서 기사의 제목과 링크가 어떤 HTML 구조를 가지고 있는지 확인해보겠습니다.
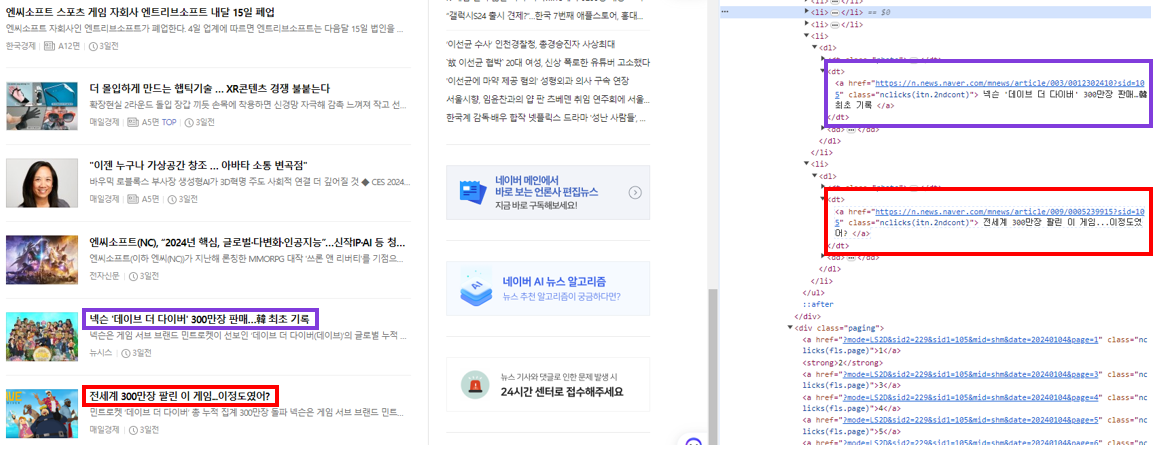
HTML 구조를 확인해보니 아래와 같이 나왔습니다.
<dt>
<a href="https://n.news.naver.com/mnews/article/009/0005239915?sid=105" class="nclicks(itn.2ndcont)">
전세계 300만장 팔린 이 게임...이정도였어? </a>
</dt>
이전 페이지 수의 HTML 구조와 매우 유사한 것을 알 수 있습니다.
저희가 수집해야 할 정보는 아래와 같습니다.
- 기사의 제목은 dt태그 속 a태그 HTML 구조의 텍스트
- 기사의 링크는 dt태그 속 a태그 HTML 구조의 href
해당 부분을 코드로 변경하면 아래와 같습니다.
※ 페이지 수와 다른 방법으로 크롤링하기 위해서 dt 태그 속 a태그로 지정하였지만, 페이지 수와 마찬가지로 a태그와 class 이름으로 지정하여도 동일한 결과물을 얻을 수 있습니다.
respose = requests.get(page_link, headers={'User-Agent':'Moailla/5.0'})
html = respose.content
soup = BeautifulSoup(html, 'html.parser')
# 정보가 담긴 a태그 바로 위의 태그인 dt태그를 전부 찾아준다.
# dt태그는 오직 기사와 관련된 부분에만 존재하는 태그로, a태그의 범위를 좁히는 목적으로만 사용한다.
# 페이지 수를 찾는 방법과 동일하게 a태그와 class이름으로 지정해도 상관없다.
Info = soup.find_all('dt')
for info in Info :
# 기사의 제목
# strip을 사용하여 눈으로 확인할 수 없는 양 끝의 공백을 잘라준다.
title = info.find('a').text.strip()
# HTML 태그가 잘못 들어오는 경우가 종종 있어서 해당 부분을 적어준다.
# 텍스트가 없는 것은 기사로 판단하지 않아서 해당 부분의 데이터는 넘어가는 것으로 진행한다.
if title == '' :
continue
# href 부분을 가져오는 방법
# a태그 내 href를 가져오는 의미이다.
link = info.find('a')["href"]
# 번호는 0부터 시작하기 때문에 1을 더해준다.
li = [number+1, title, link]
Main_link.loc[number] = li
number = number+1- 엑셀 파일로 저장
크롤링 작업은 완료하였습니다.
이제 크롤링한 데이터프레임을 엑셀 파일로 저장하도록 하겠습니다.
# 엑셀을 잘 관리하기 위해서 크롤링 날짜를 파일 이름에 포함한다.
excel_name = 'news_' + date + '.xlsx'
with pd.ExcelWriter(excel_name) as writer :
Main_link.to_excel(writer, sheet_name='링크', index=False)
이런 과정을 통해서 특정 날짜의 모든 기사의 제목과 링크를 크롤링하는 코드가 완성되었습니다!!
<전체 코드>
from bs4 import BeautifulSoup
import requests
import pandas as pd
from openpyxl import *
link = 'https://news.naver.com/main/list.naver?mode=LS2D&sid2=229&sid1=105&mid=shm&date='
date = '20240104'
main_link = link + date
Main_link = pd.DataFrame({'number' : [], 'title' : [], 'link' : []})
respose = requests.get(main_link, headers={'User-Agent':'Moailla/5.0'})
html = respose.content
soup = BeautifulSoup(html, 'html.parser')
Page = soup.find_all('a', {'class' : 'nclicks(fls.page)'})
try :
end_page = Page[-1].text
except :
end_page = 1
number = 0
for i in range(1, int(end_page)+1) :
page_link = main_link + '&page=' + str(i)
respose = requests.get(page_link, headers={'User-Agent':'Moailla/5.0'})
html = respose.content
soup = BeautifulSoup(html, 'html.parser')
Info = soup.find_all('dt')
for info in Info :
title = info.find('a').text.strip()
if title == '' :
continue
link = info.find('a')["href"]
li = [number+1, title, link]
Main_link.loc[number] = li
number = number+1
excel_name = 'news_' + date + '.xlsx'
with pd.ExcelWriter(excel_name) as writer :
Main_link.to_excel(writer, sheet_name='링크', index=False)저는 이번에 Xpath, CSS_Selector를 사용하지 않았는데, 해당 부분을 사용하면 쉽게 크롤링을 할 수 있지만
HTML 코드가 복잡하거나 크롤링을 배우고 싶은 분들에게는 좋은 방법이 아니라고 생각합니다.
기사의 본문을 크롤링하는 두 번째 코드의 자세한 크롤링 코딩 과정을 확인하고 싶으신 분들은 아래 링크를 확인해주세요!!
https://yhj9855.com/entry/Crawling-%EB%84%A4%EC%9D%B4%EB%B2%84-%EB%89%B4%EC%8A%A4-%ED%81%AC%EB%A1%A4%EB%A7%81-3
[Crawling] 네이버 뉴스 크롤링 - 3
안녕하세요. 오늘은 기존에 작성한 네이버 뉴스 크롤링 코드에서 두 번째 코드의 자세한 크롤링 과정을 포스팅 하겠습니다. 네이버 뉴스 크롤링 전체 코드를 확인하고 싶으신 분들은 아래 링크
yhj9855.com
코드에 대해 궁금한 점이 있으신 분들은 댓글로 남겨주시면, 답변 드리겠습니다.

★ 읽어주셔서 감사합니다★
'Python(파이썬) > Crawling(크롤링)' 카테고리의 다른 글
| [Crawling] 원신 나무위키 (캐릭터, 성유물) 크롤링 - 1 (51) | 2024.03.31 |
|---|---|
| [Crawling] 네이버 뉴스 크롤링 코드 변경 (40) | 2024.03.27 |
| [Crawling] 네이버 뉴스 크롤링 - 3 (72) | 2024.01.11 |
| [Crawling] 네이버 뉴스 크롤링 - 1 (57) | 2024.01.05 |