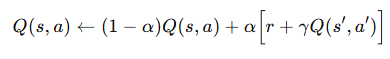안녕하세요! 오늘은 gymnasium에서 제공하는 cart pole 문제 설명에 대한 포스팅 진행하겠습니다.
저는 cart pole 문제를 DQN과 DDQN 두 가지 방법으로 풀어보았는데요!
각각 전체 코드는 포스팅 가장 아래에 있습니다.
- cart pole 규칙
우선 gymnasium에서 제공하는 cart pole 문제는 아래 링크에서 자세하게 보실 수 있습니다.
https://gymnasium.farama.org/environments/classic_control/cart_pole/
Gymnasium Documentation
A standard API for reinforcement learning and a diverse set of reference environments (formerly Gym)
gymnasium.farama.org

위의 사진처럼 생긴 막대를 지속적으로 세우는 것이 cart pole의 가장 큰 목표 입니다.
cart pole의 자세한 규칙은 아래와 같습니다.
- 이동 방향은 좌, 우만 존재
- 현재 막대의 상태는 막대 위치, 속도, 각도, 각속도 총 4가지로 표현
- 하나의 step이 에피소드 종료되지 않으면 보상 1을 획득
- 각도가 좌우 12 º 이상 벗어나거나, 막대가 화면을 벗어나거나, 보상 500(혹은 200) 달성하면 에피소드 종료
저희는 위의 규칙을 잘 생각하여, 막대가 특정 각도를 넘어가거나 화면에 벗어나지 않게 500 에피소드 이상 버티는 것을 학습해주어야 합니다.
- 필요한 라이브러리 설치
frozen lake는 gymnasium에서 제공하고 있기 때문에 가장 먼저 gymnasium을 설치해주시면 됩니다!
그리고 render 모드 활성화를 진행하기 위해 gymnasium[toy-text] 설치도 같이 진행해주세요.
두 패키지 모두 pip install로 설치해주시면 금방 설치할 수 있습니다.
import gymnasium as gym
from collections import defaultdict
import numpy as np- cart pole 환경 세팅
필요한 라이브러리를 설치한 후에는 cart pole 환경을 세팅해봅니다.
우선 환경 세팅을 하는 코드는 아래와 같습니다.
env = gym.make("CartPole-v1")cart pole은 학습을 진행해주지 않으면 바로 에피소드가 종료가 되기 때문에 테스트를 진행해보기가 어렵습니다ㅠㅠ
어떤 식으로 진행되는지 궁금하신 분들은 전체 코드 복사 후 실행해보시면, cart pole이 어떻게 진행되는지 아실 수 있습니다!
여기까지가 cart pole 환경 세팅이었습니다.
cart pole 환경 세팅은 그렇게 어렵지 않아서, 금방 하실 수 있어요!
이번 포스팅에서는 DQN과 DDQN에 관한 전체 코드만 업로드하고, 자세한 포스팅은 추후에 진행하도록 하겠습니다.
두 가지 모두 500 에피소드에 달성한 모델이 다수 존재했습니다.
[DQN 전체 코드]
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
import random
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
import os
import glob
import torch.nn.functional as F
# 하이퍼 파라미터
gamma = 0.99
learning_rate = 0.001
batch_size = 100
memory_size = 5000
# epsilon에 의해 행동을 선택할 때는 해당 부분 필요
# epsilon_start = 1.0
# epsilon_end = 0.001
# epsilon_decay = 0.995
episodes = 5000
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
class ReplayMemory:
def __init__(self, max_len):
self.memory = deque(maxlen=max_len)
def push(self, transition):
self.memory.append(transition)
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
def select_action(state, target_net, action_dim):
# epsilon-greedy를 바탕으로 행동을 선택하는 과정
# if random.random() < epsilon:
# return random.randint(0, action_dim - 1)
# else:
# return target_net(state).argmax().item()
# 행동 값을 확률로 변경하여, 확률에 따라 행동을 선택하는 과정
q_value = target_net(state)
p = F.softmax(q_value, dim=0).tolist()
p = np.array(p)
p /= p.sum()
action = np.random.choice(action_dim, p=p)
return action
def optimize_model(memory, policy_net, target_net, optimizer):
if len(memory) < batch_size:
return
transitions = memory.sample(batch_size)
batch = list(zip(*transitions))
state_batch = torch.stack(batch[0])
action_batch = torch.tensor(batch[1]).unsqueeze(1)
reward_batch = torch.tensor(batch[2])
next_state_batch = torch.stack(batch[3])
done_batch = torch.tensor(batch[4], dtype=torch.float32)
# DQN
q_values = policy_net(state_batch).gather(1, action_batch)
next_q_values = target_net(next_state_batch).max(1)[0].detach()
target_q_values = reward_batch + (gamma * next_q_values * (1 - done_batch))
loss = nn.MSELoss()(q_values.squeeze(), target_q_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
policy_net = DQN(state_dim, action_dim)
target_net = DQN(state_dim, action_dim)
target_net.load_state_dict(policy_net.state_dict())
target_net.eval()
optimizer = optim.Adam(policy_net.parameters(), lr=learning_rate)
memory = ReplayMemory(memory_size)
# epsilon-greedy 방법으로 행동을 선택할 때 필요
# epsilon = epsilon_start
episode_rewards = []
episode_reward = 0
save_dir = "dqn_saved_models"
os.makedirs(save_dir, exist_ok=True)
# 500을 10회 진행하면 성공이라고 판단하여, 종료를 하기 위한 장치로 잠깐 쓰인 것
# count = 0
for episode in range(episodes):
# if count > 10 :
# break
state = torch.tensor(env.reset()[0], dtype=torch.float32)
if episode % 1000 == 0:
print(f"Episode {episode}, Avg Reward: {episode_reward/1000}")
if episode % 1000 == 0 :
episode_reward = 0
total_reward = 0
# 500 초과인 경우는 done으로 판단
while total_reward < 501 :
action = select_action(state, target_net, action_dim)
next_state, reward, done, _, _ = env.step(action)
next_state = torch.tensor(next_state, dtype=torch.float32)
memory.push((state, action, reward, next_state, done))
state = next_state
total_reward += reward
optimize_model(memory, policy_net, target_net, optimizer)
if done :
break
# 500점 달성한 모델 저장
if total_reward >= 500 :
# count += 1
model_path = os.path.join(save_dir, f"dqn_model_episode_{episode}.pth")
torch.save(policy_net.state_dict(), model_path)
episode_reward += total_reward
# epsilon-greedy로 action을 선택할 때는 있어야 함
# if episode % 10 == 0 :
# epsilon = max(epsilon_end, epsilon*epsilon_decay)
if episode % 20 == 0:
target_net.load_state_dict(policy_net.state_dict())
episode_rewards.append(total_reward)
plt.plot(episode_rewards)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('DQN on CartPole')
plt.show()
# 테스트 진행 - render를 켜줘야 확인이 가능
env = gym.make("CartPole-v1", render_mode='human')
# 500 달성한 모델 업로드
model_paths = glob.glob(os.path.join(save_dir, "*.pth"))
model_i = 0
for model_path in model_paths :
policy_net.load_state_dict(torch.load(model_path))
policy_net.eval()
avg_reward = 0
# 각 모델 별 10번 진행
for episode in range(10) :
state = torch.tensor(env.reset()[0], dtype=torch.float32)
total_reward = 0
while total_reward < 501 :
with torch.no_grad() :
action = policy_net(state).argmax().item()
next_state, reward, done, _, _ = env.step(action)
next_state = torch.tensor(next_state, dtype=torch.float32)
state = next_state
total_reward += reward
if done :
break
avg_reward += total_reward
print(f"model {model_i + 1}, Avg Reward: {avg_reward/10}")
model_i += 1
[DDQN 전체 코드]
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
import random
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
import os
import glob
import torch.nn.functional as F
# 하이퍼 파라미터
gamma = 0.99
learning_rate = 0.001
batch_size = 100
memory_size = 5000
# epsilon에 의해 행동을 선택할 때는 해당 부분 필요
# epsilon_start = 1.0
# epsilon_end = 0.001
# epsilon_decay = 0.995
episodes = 5000
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
class ReplayMemory:
def __init__(self, max_len):
self.memory = deque(maxlen=max_len)
def push(self, transition):
self.memory.append(transition)
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
def select_action(state, target_net, action_dim):
# epsilon-greedy를 바탕으로 행동을 선택하는 과정
# if random.random() < epsilon:
# return random.randint(0, action_dim - 1)
# else:
# return target_net(state).argmax().item()
# 행동 값을 확률로 변경하여, 확률에 따라 행동을 선택하는 과정
q_value = target_net(state)
p = F.softmax(q_value, dim=0).tolist()
p = np.array(p)
p /= p.sum()
action = np.random.choice(action_dim, p=p)
return action
def optimize_model(memory, policy_net, target_net, optimizer):
if len(memory) < batch_size:
return
transitions = memory.sample(batch_size)
batch = list(zip(*transitions))
state_batch = torch.stack(batch[0])
action_batch = torch.tensor(batch[1]).unsqueeze(1)
reward_batch = torch.tensor(batch[2])
next_state_batch = torch.stack(batch[3])
done_batch = torch.tensor(batch[4], dtype=torch.float32)
# DDQN
q_values = policy_net(state_batch).gather(1, action_batch)
next_action = policy_net(next_state_batch).argmax(1).unsqueeze(1)
next_q_values = target_net(next_state_batch).gather(1, next_action).squeeze().detach()
target_q_values = reward_batch + (gamma * next_q_values * (1 - done_batch))
loss = nn.MSELoss()(q_values.squeeze(), target_q_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
policy_net = DQN(state_dim, action_dim)
target_net = DQN(state_dim, action_dim)
target_net.load_state_dict(policy_net.state_dict())
target_net.eval()
optimizer = optim.Adam(policy_net.parameters(), lr=learning_rate)
memory = ReplayMemory(memory_size)
# epsilon-greedy 방법으로 행동을 선택할 때 필요
# epsilon = epsilon_start
episode_rewards = []
episode_reward = 0
save_dir = "dqn_saved_models"
os.makedirs(save_dir, exist_ok=True)
# 500을 10회 진행하면 성공이라고 판단하여, 종료를 하기 위한 장치로 잠깐 쓰인 것
# count = 0
for episode in range(episodes):
# if count > 10 :
# break
state = torch.tensor(env.reset()[0], dtype=torch.float32)
if episode % 1000 == 0:
print(f"Episode {episode}, Avg Reward: {episode_reward/1000}")
if episode % 1000 == 0 :
episode_reward = 0
total_reward = 0
# 500 초과인 경우는 done으로 판단
while total_reward < 501 :
action = select_action(state, target_net, action_dim)
next_state, reward, done, _, _ = env.step(action)
next_state = torch.tensor(next_state, dtype=torch.float32)
memory.push((state, action, reward, next_state, done))
state = next_state
total_reward += reward
optimize_model(memory, policy_net, target_net, optimizer)
if done :
break
# 500점 달성한 모델 저장
if total_reward >= 500 :
# count += 1
model_path = os.path.join(save_dir, f"dqn_model_episode_{episode}.pth")
torch.save(policy_net.state_dict(), model_path)
episode_reward += total_reward
# epsilon-greedy로 action을 선택할 때는 있어야 함
# if episode % 10 == 0 :
# epsilon = max(epsilon_end, epsilon*epsilon_decay)
if episode % 20 == 0:
target_net.load_state_dict(policy_net.state_dict())
episode_rewards.append(total_reward)
plt.plot(episode_rewards)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('DDQN on CartPole')
plt.show()
# 테스트 진행 - render를 켜줘야 확인이 가능
env = gym.make("CartPole-v1", render_mode='human')
# 500 달성한 모델 업로드
model_paths = glob.glob(os.path.join(save_dir, "*.pth"))
model_i = 0
for model_path in model_paths :
policy_net.load_state_dict(torch.load(model_path))
policy_net.eval()
avg_reward = 0
# 각 모델 별 10번 진행
for episode in range(10) :
state = torch.tensor(env.reset()[0], dtype=torch.float32)
total_reward = 0
while total_reward < 501 :
with torch.no_grad() :
action = policy_net(state).argmax().item()
next_state, reward, done, _, _ = env.step(action)
next_state = torch.tensor(next_state, dtype=torch.float32)
state = next_state
total_reward += reward
if done :
break
avg_reward += total_reward
print(f"model {model_i + 1}, Avg Reward: {avg_reward/10}")
model_i += 1결과물


코드에 궁금한 부분이 있으신 분들은 댓글로 남겨주시면, 답변 드리도록 하겠습니다.

★읽어주셔서 감사합니다★
'Python(파이썬) > RL (강화 학습)' 카테고리의 다른 글
| [RL] gymnasium frozen lake 강화 학습 - SARSA (1) | 2025.02.11 |
|---|---|
| [RL] gymnasium frozen lake 강화 학습 - 2 (2) | 2025.02.03 |
| [RL] gymnasium frozen lake 강화 학습 - 1 (1) | 2025.01.22 |